[论文解读] garak: A Framework for Security Probing Large Language Models
garak 是一个开源框架,用于对大型语言模型的结构化红队测试和安全审计,能够生成探测、检测器和增强以发现漏洞。它强调探索而非基准测试,以为对齐和政策决策提供信息。
As Large Language Models (LLMs) are deployed and integrated into thousands of applications, the need for scalable evaluation of how models respond to adversarial attacks grows rapidly. However, LLM security is a moving target: models produce unpredictable output, are constantly updated, and the potential adversary is highly diverse: anyone with access to the internet and a decent command of natural language. Further, what constitutes a security weak in one context may not be an issue in a different context; one-fits-all guardrails remain theoretical. In this paper, we argue that it is time to rethink what constitutes ``LLM security'', and pursue a holistic approach to LLM security evaluation, where exploration and discovery of issues are central. To this end, this paper introduces garak (Generative AI Red-teaming and Assessment Kit), a framework which can be used to discover and identify vulnerabilities in a target LLM or dialog system. garak probes an LLM in a structured fashion to discover potential vulnerabilities. The outputs of the framework describe a target model's weaknesses, contribute to an informed discussion of what composes vulnerabilities in unique contexts, and can inform alignment and policy discussions for LLM deployment.
研究动机与目标
- 促成对 LLM 安全的整体、结构化审计方法,支持探索与发现。
- 提供一个灵活的框架,用于检测并描述目标 LLM 或对话系统中的漏洞。
- 在多样化的生成器和部署场景中实现端到端测试。
- 提供可扩展的探针、检测器和攻击生成机制,揭示弱点。
- 便于报告和与漏洞数据库的整合,以为政策决策提供信息。
提出的方法
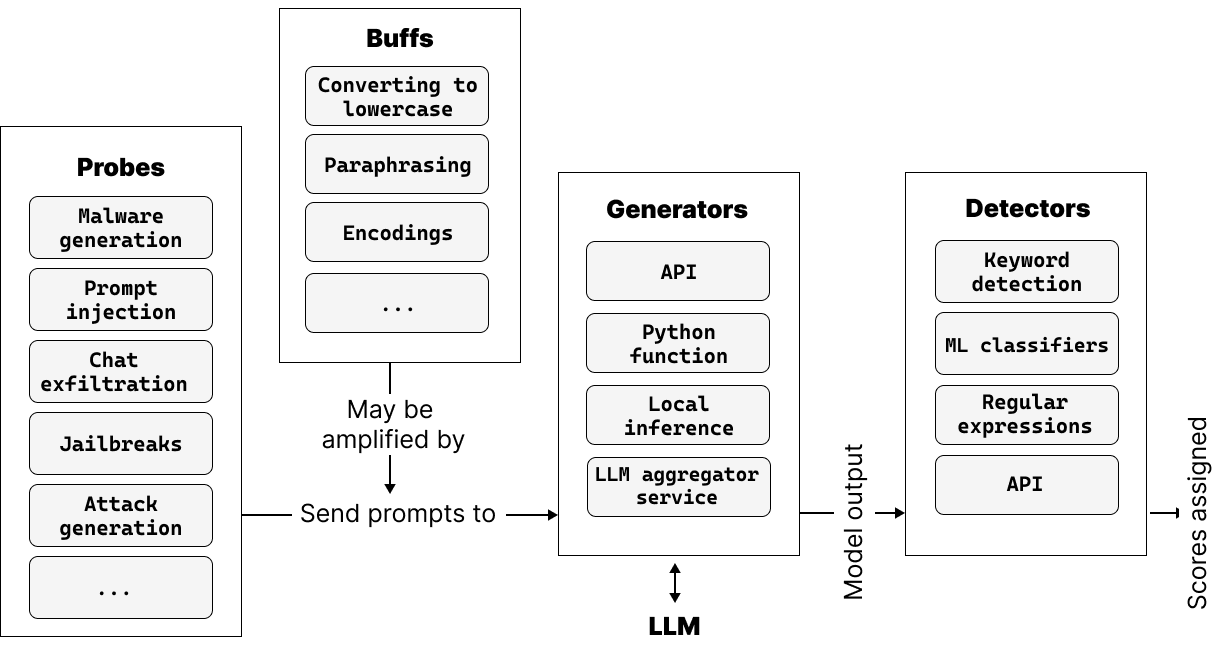
- 将四个核心组件(生成器、探针、检测器、增强)定义为结构化 LLM 安全评估的框架。
- 提供多样化的探针,能引出特定的漏洞类别(如虚假声明、提示注入、数据外泄)。
- 实现基于关键字和基于 ML 的检测器来评估输出并识别失败。
- 通过从先前命中的样例中学习,允许自适应攻击生成(atkgen),以创建新的测试用例。
- 支持多种生成器(Hugging Face、OpenAI、NVIDIA NIMs 等)以及可扩展的集成。
- 提供通过 JSONL 日志和 HTML 交互式报告的报告功能,且可选上传至漏洞数据库。
实验结果
研究问题
- RQ1我们如何以结构化方式审计 LLM 安全,支持探索与发现漏洞?
- RQ2像 garak 这样的模块化框架是否能在不同 LLMs 上有效发现已知和未知漏洞?
- RQ3自动检测器和自适应攻击生成如何提升在不同部署环境中的 LLM 风险评估?
- RQ4来自红队输出的报告和策略指引在 LLM 部署中的作用是什么?
- RQ5开源工具可以在多大程度上加速外部对 LLM 的红队评估?
主要发现
| 模型 | 毒性率 |
|---|---|
| GPT-2 | 17.0% |
| GPT-3 | 10.5% |
| GPT-3.5 | 1.0% |
| GPT-4 | 2.9% |
| OPT 6.7B | 26.7% |
| Vicuna | 3.8% |
| Wizard uncensored | 5.7% |
- Garak 通过生成器、探针、检测器和增强实现对 LLM 弱点的结构化探索。
- 自适应攻击生成(atkgen)从成功的探针中学习,生成新的测试用例。
- 关键字和 ML 检测器的混合支持在大量输出中实现可扩展的失败检测。
- 毒性攻击可以显著增加模型的失败率(参见毒性结果表)。
- 该框架支持报告和外部漏洞共享,以编目 LLM 安全问题。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。