[论文解读] Gemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations
本文在医疗推理、幻觉风险(Med-HALT)和医疗 VQA 方面,对 Google Gemini 与开源和商业医疗 LLM 进行评估,使用 MultiMedQA、Med-HALT 和 NEJM-VQA 基准,并提供提示策略和评估工具。Gemini 在若干医疗任务上落后于 Med-PaLM 2 与 GPT-4,并显示出显著的幻觉风险,但通过提示技术有所改进。
Large language models have the potential to be valuable in the healthcare industry, but it's crucial to verify their safety and effectiveness through rigorous evaluation. For this purpose, we comprehensively evaluated both open-source LLMs and Google's new multimodal LLM called Gemini across Medical reasoning, hallucination detection, and Medical Visual Question Answering tasks. While Gemini showed competence, it lagged behind state-of-the-art models like MedPaLM 2 and GPT-4 in diagnostic accuracy. Additionally, Gemini achieved an accuracy of 61.45\% on the medical VQA dataset, significantly lower than GPT-4V's score of 88\%. Our analysis revealed that Gemini is highly susceptible to hallucinations, overconfidence, and knowledge gaps, which indicate risks if deployed uncritically. We also performed a detailed analysis by medical subject and test type, providing actionable feedback for developers and clinicians. To mitigate risks, we applied prompting strategies that improved performance. Additionally, we facilitated future research and development by releasing a Python module for medical LLM evaluation and establishing a dedicated leaderboard on Hugging Face for medical domain LLMs. Python module can be found at https://github.com/promptslab/RosettaEval
研究动机与目标
- 评估 Gemini 在文本与视觉模态下的医疗推理能力。
- 量化 Gemini 在医疗情境中的幻觉倾向与安全风险。
- 在医疗基准上将 Gemini 与开源 LLM 和商业模型进行比较。
- 提供可操作的提示策略与模型改进的反馈。
- 发布评估工具和医疗领域排行榜,促进可重复研究。
提出的方法
- 通过 Gemini Pro 开发者 API 在确定性设置下评估 Gemini Pro(温度 0.0,top-p 1.0)。
- 在 MultiMedQA、Med-HALT 和 Medical Visual Question Answering 上使用提示技术进行基准测试(零样本、少样本、思考链、自洽性、集成精炼)。
- 与开源 LLM(Llama 系列、Mistral、Yi-34b、Qwen-72b 等)及闭源模型(MedPaLM、MedPaLM 2、GPT-4)进行比较。
- 以准确率作为 MultiMedQA 和 VQA 的主要指标;对 Med-HALT 评估使用 Pointwise Score。
- 引入 RosettaEval Python 模块用于医疗 LLM 评估,并建立 Hugging Face 的医疗 LLM 排行榜。
实验结果
研究问题
- RQ1Gemini 在文本与图像上的复杂医疗推理题目上能多准确地解决?
- RQ2Gemini 的医疗回答是否存在幻觉或过度自信?
- RQ3在标准基准上,Gemini 的表现与开源及商业医疗 LLM 相比如何?
- RQ4哪些提示策略能提升 Gemini 的医疗推理并减少幻觉?
- RQ5Gemini 在医疗知识和多模态能力方面存在哪些领域特定的强项与弱点?
主要发现
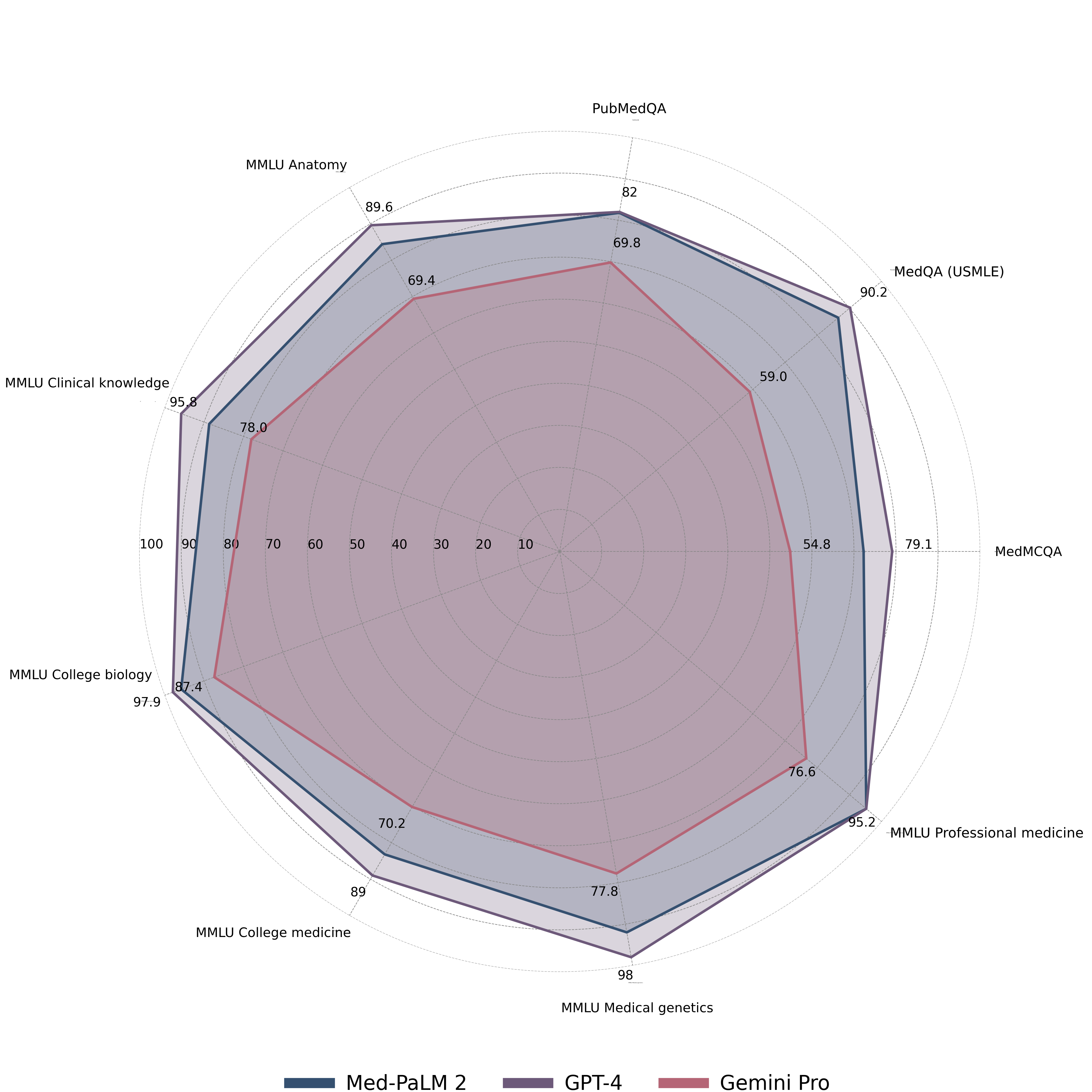
- Gemini Pro 在 MultiMedQA 基准上表现强劲但未达到最前沿,与 Med-PaLM 2 和 GPT-4 相比(如讨论中的 MedQA USMLE 和 MedMCQA 结果)。
- 在 Med-HALT 上,Gemini 对 Reasoning Fake 的准确性很高,但对过度自信的保护不足(Reasoning FCT)以及基于记忆的检索挑战(IR PubMedlink 任务)表现较差。
- Gemini Pro 的医疗 VQA 准确率为 61.45%,显著低于 GPT-4V 的 88%。
- 面向学科的分析显示 Gemini 在 生物统计、流行病学、细胞生物学以及某些领域(如胃肠病学、产科与妇科)表现出色,但在其他医学子领域和复杂推理任务上表现不佳。
- 提示策略如 Chain-of-Thought 与 Ensemble Refinement 可以在特定领域改善性能,尽管效应因数据集而异;零样本和少样本提示在不同任务上呈现不同增益。
- 作者提供了一个 Python 评估模块(RosettaEval)并建立了 Hugging Face 排行榜,以支持可重复的医疗 LLM 研究。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。