[论文解读] Generative Sequential Recommendation with GPTRec
GPTRec 是基于 GPT-2 的生成式序列推荐,使用基于 SVD 的子项标记以减少内存,引入 Next-K 生成,在排序上与 SASRec 相当,同时实现内存效率与灵活生成。
Sequential recommendation is an important recommendation task that aims to predict the next item in a sequence. Recently, adaptations of language models, particularly Transformer-based models such as SASRec and BERT4Rec, have achieved state-of-the-art results in sequential recommendation. In these models, item ids replace tokens in the original language models. However, this approach has limitations. First, the vocabulary of item ids may be many times larger than in language models. Second, the classical Top-K recommendation approach used by these models may not be optimal for complex recommendation objectives, including auxiliary objectives such as diversity, coverage or coherence. Recent progress in generative language models inspires us to revisit generative approaches to address these challenges. This paper presents the GPTRec sequential recommendation model, which is based on the GPT-2 architecture. GPTRec can address large vocabulary issues by splitting item ids into sub-id tokens using a novel SVD Tokenisation algorithm based on quantised item embeddings from an SVD decomposition of the user-item interaction matrix. The paper also presents a novel Next-K recommendation strategy, which generates recommendations item-by-item, considering already recommended items. The Next-K strategy can be used for producing complex interdependent recommendation lists. We experiment with GPTRec on the MovieLens-1M dataset and show that using sub-item tokenisation GPTRec can match the quality of SASRec while reducing the embedding table by 40%. We also show that the recommendations generated by GPTRec on MovieLens-1M using the Next-K recommendation strategy match the quality of SASRec in terms of NDCG@10, meaning that the model can serve as a strong starting point for future research.
研究动机与目标
- 推动在序列推荐中使用生成式模型,以应对庞大物品词表和超越 Top-K 的灵活目标。
- 引入通过 SVD 实现的高效标记化,将物品 ID 拆分为子项标记以降低内存占用。
- 提出 Next-K 生成策略,使推荐列表之间相互依赖并支持复杂目标。
- 给出基于 GPT-2 的 GPTRec 架构,并在 MovieLens-1M 上与 SASRec 及 BERT4Rec 进行对比。
提出的方法
- 采用 GPT-2 解码器架构并以交叉熵损失对物品标记的序列建模。
- 引入 SVD Tokenisation:从用户-物品矩阵的量化 SVD 嵌入中,为每个物品创建 t 个子项标记。
- 允许单标记/物品一个标记与多标记/物品一个标记两种模式,以在内存使用和生成之间取得平衡。
- 实现 Top-K 与 Next-K 生成策略,包括 Next-K 的逐步生成评分。
- 在 MovieLens-1M 上使用留一法设置、最大序列长度为 100 的 3 层 Transformer 进行评估。
- 将 GPTRec 的变体(GPTRec-TopK、GPTRec-NextK)与 SASRec 与 BERT4Rec 进行对比,使用 Recall@10 和 NDCG@10。
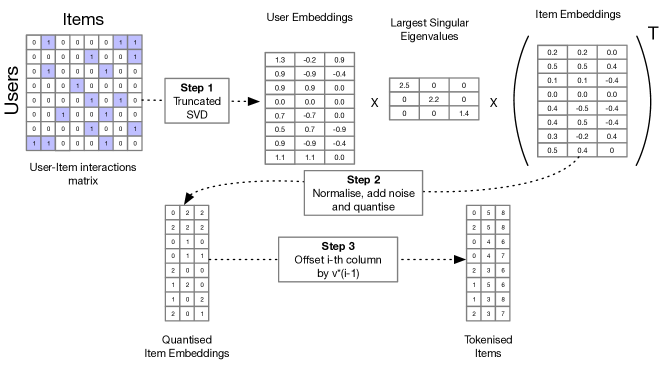
实验结果
研究问题
- RQ1GPTRec 在单项标记/标识模式下的表现如何,与 BERT4Rec 和 SASRec 相比?
- RQ2在 GPTRec 的多标记/项模式中,标记数量与每个标记值的数量对性能有何影响?
- RQ3Next-K 推荐模式中切分阈值 K 的设置对 GPTRec 性能有何影响?
主要发现
| 模型名称 | 生成策略 | 架构 | 训练任务 | 损失 | Recall@10 | NDCG@10 |
|---|---|---|---|---|---|---|
| BERT4Rec | TopK | Encoder | MLM (Item Masking) | Cross Entropy (Softmax Loss) | 0.282 | 0.152 |
| GPTRec-TopK | TopK | Decoder | LM (Sequence Shifting) | Cross Entropy (Softmax Loss) | 0.254 | 0.146 |
| SASRec | TopK | Decoder | LM (Sequence Shifting) | Binary Cross-Entropy | 0.199 | 0.108 |
| GPTRec-NextK | NextK | Decoder | LM (Sequence Shifting) | Cross Entropy (Softmax Loss) | 0.157 | 0.105 |
- GPTRec-NextK 在 MovieLens-1M 上实现 Recall@10 0.157 和 NDCG@10 0.105,与 SASRec 的 Recall@10 0.199 和 NDCG@10 0.108 相当。
- GPTRec-TopK 在 Recall@10 0.254 和 NDCG@10 0.146,在 Top-K 设置下这两项指标超越 SASRec。
- BERT4Rec 的 Recall@10 为 0.282、NDCG@10 为 0.152,在所给表格中高于 GPTRec 的变体。
- SVD Tokenisation 显著降低嵌入记忆使用(例如 t=8、v=2048 时内存为 16 MB,而某些尺度下单标记/项超过 10 GB)。
- GPTRec 的 Next-K 模式提供一个灵活的生成框架,能够在保持具有竞争力排序质量的同时解决复杂目标。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。