[论文解读] GRAG: Graph Retrieval-Augmented Generation
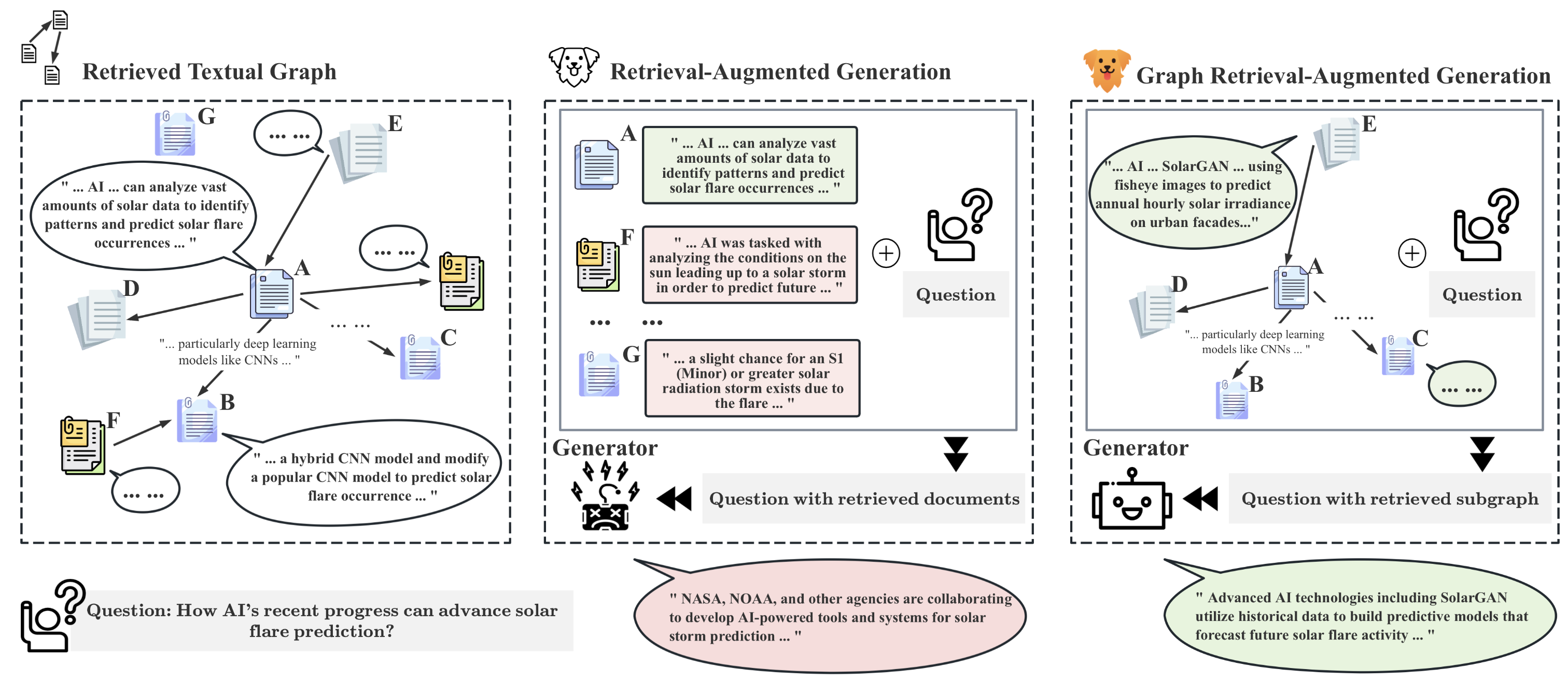
GRAG 检索与查询相关的文本子图,使用软 pruning 和 双重提示(硬文本提示 + 软图提示)来增强基于图的多跳推理的LLMs,优于传统的RAG方法并减少幻觉。
Naive Retrieval-Augmented Generation (RAG) focuses on individual documents during retrieval and, as a result, falls short in handling networked documents which are very popular in many applications such as citation graphs, social media, and knowledge graphs. To overcome this limitation, we introduce Graph Retrieval-Augmented Generation (GRAG), which tackles the fundamental challenges in retrieving textual subgraphs and integrating the joint textual and topological information into Large Language Models (LLMs) to enhance its generation. To enable efficient textual subgraph retrieval, we propose a novel divide-and-conquer strategy that retrieves the optimal subgraph structure in linear time. To achieve graph context-aware generation, incorporate textual graphs into LLMs through two complementary views-the text view and the graph view-enabling LLMs to more effectively comprehend and utilize the graph context. Extensive experiments on graph reasoning benchmarks demonstrate that in scenarios requiring multi-hop reasoning on textual graphs, our GRAG approach significantly outperforms current state-of-the-art RAG methods. Our datasets as well as codes of GRAG are available at https://github.com/HuieL/GRAG.
研究动机与目标
- 在拓扑结构比文本本身更重要的文本图上推动稳健推理。
- 提出一种高效的子图检索机制,以应对 NP-hard 子图搜索。
- 在检索和生成过程中同时保留文本内容和图的拓扑结构。
- 引入一种无损地将文本子图转换为适合 LLM 的分层描述的提示策略。
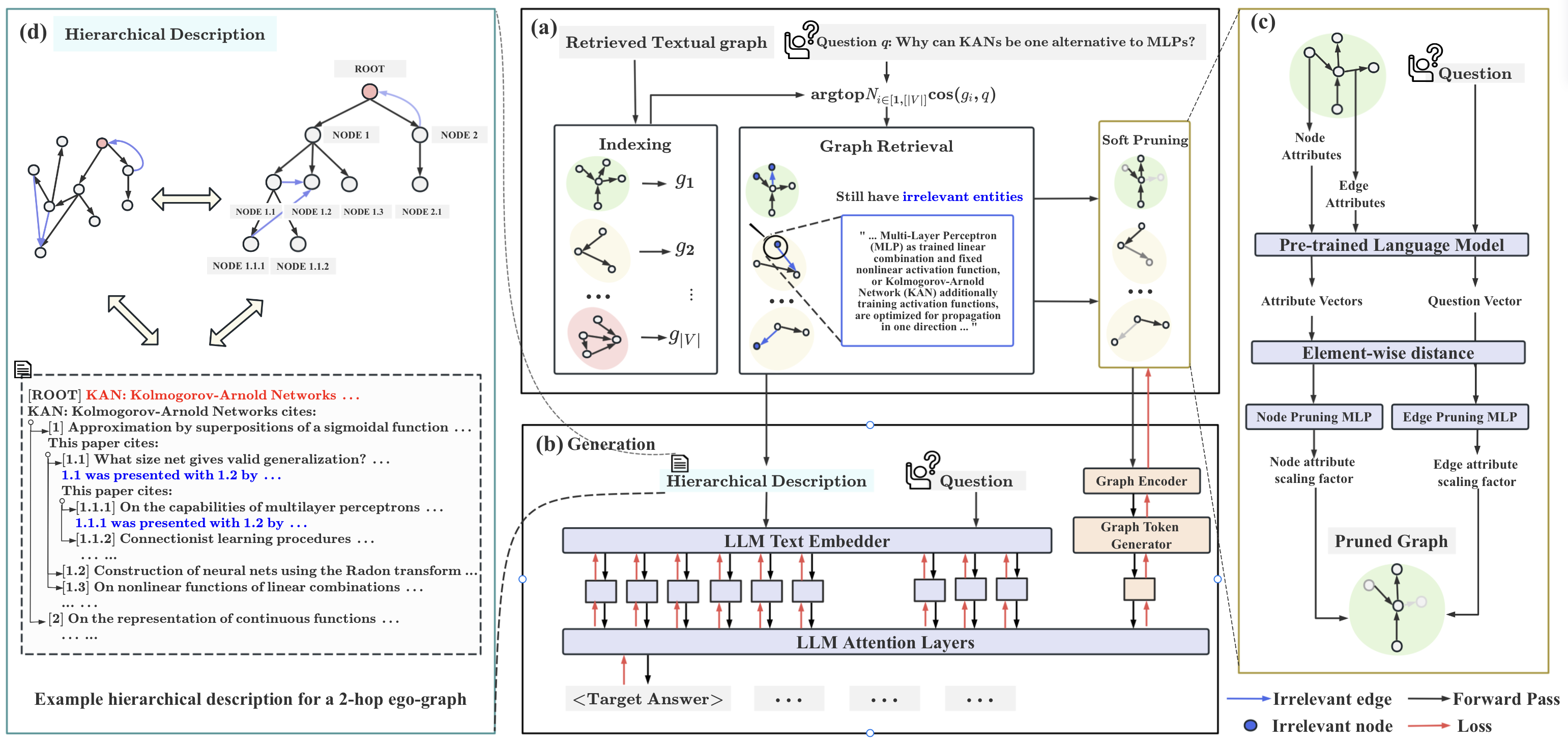
提出的方法
- 对 k 跳的自我图进行索引,并使用预训练语言模型将其编码为图嵌入。
- 通过问题嵌入与子图嵌入的余弦相似度检索前 N 个文本子图。
- 应用软 prune,通过从问题-子图距离学习的相关性标量来缩放节点/边的贡献。
- 通过将硬提示(子图的分层文本描述)与软提示(图嵌入)相结合来生成答案,并通过 GNN 和 MLP 将图嵌入与 LLM 文本向量对齐。
实验结果
研究问题
- RQ1在大型文本图中如何在不进行穷举搜索的情况下高效地检索与查询相关的子图?
- RQ2在生成过程中如何同时保存和整合文本信息与拓扑信息?
- RQ3一个被冻结的 LLM 加上检索子图,是否能在图推理任务上超越微调的 LLM 的基线?
- RQ4软提示是否能在不产生巨大训练成本的情况下有效引导图感知生成?
主要发现
| 模型 | Φ(g) | 微调 | WebQSP F1 | WebQSP Hit@1 | WebQSP Recall | WebQSP Acc | ExplaGraphs F1 | ExplaGraphs Hit@1 | ExplaGraphs Recall | ExplaGraphs Acc |
|---|---|---|---|---|---|---|---|---|---|---|
| 仅 LLM | ✗ | ✗ | 0.2555 | 0.4148 | 0.2920 | 0.3394 | ||||
| LLM_LoRA | ✗ | ✓ | 0.4295 | 0.6186 | 0.4193 | 0.8927 | ||||
| BM25 | ✗ | ✗ | 0.2999 | 0.4287 | 0.2879 | 0.6011 | ||||
| MiniLM-L12-v2 | ✗ | ✗ | 0.3485 | 0.4730 | 0.3289 | 0.6011 | ||||
| LaBSE | ✗ | ✗ | 0.3280 | 0.4496 | 0.3126 | 0.6011 | ||||
| mContriever-Base | ✗ | ✗ | 0.3172 | 0.4453 | 0.3047 | 0.5866 | ||||
| E5-Base | ✗ | ✗ | 0.3421 | 0.4705 | 0.3254 | 0.6011 | ||||
| G-Retriever | ✓ | ✗ | 0.4674 | 0.6808 | 0.4579 | 0.8825 | ||||
| G-Retriever_LoRA | ✓ | ✓ | 0.5023 | 0.7016 | 0.5002 | 0.9042 | ||||
| GRAG | ✓ | ✗ | 0.5022 | 0.7236 | 0.5099 | 0.9223 | 0.NOP | 0.NOP | 0.NOP | 0.NOP |
| GRAG_LoRA | ✓ | ✓ | 0.5041 | 0.7275 | 0.5112 | 0.9274 | 0.NOP | 0.NOP | 0.NOP | 0.NOP |
- GRAG 在图的多跳推理基准(WebQSP 和 ExplaGraphs)上超越了最先进的 RAG 基线和仅 LLM 的方法。
- 一个带 GRAG 的冻结 LLM 在所有任务上都超越了微调的 LLM,且培训成本更低。
- 软 prune 和子图级检索减少了幻觉并提升了事实依据,来自人工评估的有效实体引用更高。
- 将检索到的子图作为软图标记使用比仅使用文本或穷举子图搜索表现更好。
- 跨数据集迁移显示在一个数据集上训练的 GRAG 可以提升另一数据集的表现(如从 WebQSP 到 ExplaGraphs)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。