[论文解读] How Does In-Context Learning Help Prompt Tuning?
本文实证分析了在上下文学习(ICL)、提示微调(PT)与指令提示微调(IPT)在五个文本生成任务中的相互作用,揭示了 IPT 或 PT 出色的情形,以及迁移与稳定性表现。
Fine-tuning large language models is becoming ever more impractical due to their rapidly-growing scale. This motivates the use of parameter-efficient adaptation methods such as prompt tuning (PT), which adds a small number of tunable embeddings to an otherwise frozen model, and in-context learning (ICL), in which demonstrations of the task are provided to the model in natural language without any additional training. Recently, Singhal et al. (2022) propose ``instruction prompt tuning'' (IPT), which combines PT with ICL by concatenating a natural language demonstration with learned prompt embeddings. While all of these methods have proven effective on different tasks, how they interact with each other remains unexplored. In this paper, we empirically study when and how in-context examples improve prompt tuning by measuring the effectiveness of ICL, PT, and IPT on five text generation tasks with multiple base language models. We observe that (1) IPT does \emph{not} always outperform PT, and in fact requires the in-context demonstration to be semantically similar to the test input to yield improvements; (2) PT is unstable and exhibits high variance, but combining PT and ICL (into IPT) consistently reduces variance across all five tasks; and (3) prompts learned for a specific source task via PT exhibit positive transfer when paired with in-context examples of a different target task. Our results offer actionable insights on choosing a suitable parameter-efficient adaptation method for a given task.
研究动机与目标
- 由于完全微调不可行,推动对大语言模型的参数高效自适应。
- 在多样的 OOD 生成任务中比较 ICL、PT 和 IPT。
- 研究 IPT 在何种条件下优于 PT 以及示例相似度的作用。
- 在使用上下文演示时,研究在一个任务上学习的软提示向其他任务的迁移性。
提出的方法
- 以 BLOOM-1.1B、OPT-1.3B 和 GPT-2-XL-1.5B 作为基础语言模型,对五个语言生成任务进行经验比较 ICL、PT 与 IPT。
- 对 PT 与 IPT 使用软提示嵌入,在初始提示之上叠加两个前馈层以提高稳定性。
- 采用密集检索(最近邻)提取上下文示例,并对每个测试样本仅评估一个检索到的示例。
- 使用随机初始化的提示训练 PT/IPT,基于开发集损失评估,并报告三次运行(AdamW 优化)的平均值。
- 评估上下文示例与测试输入之间的相似性如何影响 IPT 与 PT 的性能。
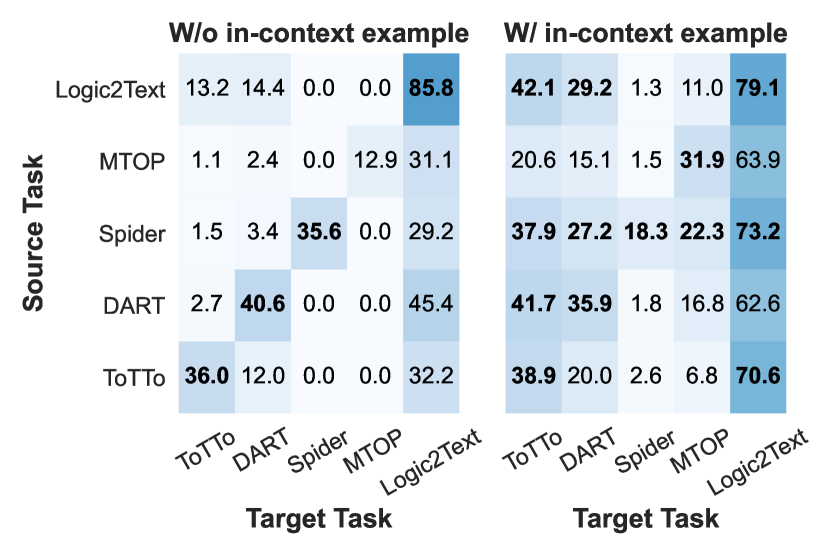
- 通过将源任务的提示与目标任务的上下文示例配对,探索跨任务迁移。
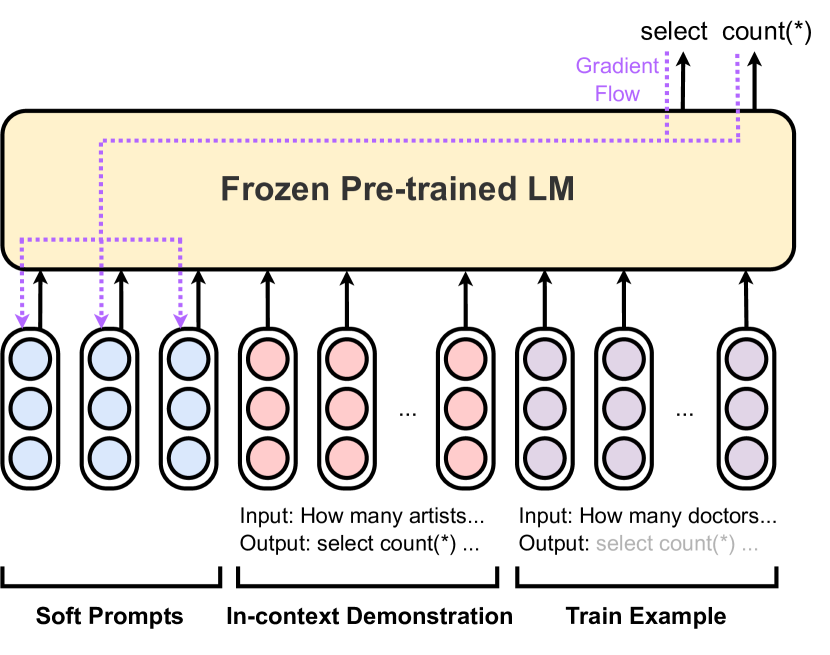
实验结果
研究问题
- RQ1在何种条件下 IPT 和 PT 能在跨域生成任务中优于 ICL?
- RQ2检索到的上下文示例与测试输入之间的相似性如何影响 IPT 与 PT 的性能?
- RQ3在调整如软提示标记数等超参数时,IPT 是否能降低 PT 的方差?
- RQ4在结合目标任务示例的情况下,源任务学习的软提示是否可以有益地迁移到新的目标任务?
- RQ5在五个不同的数据到文本、逻辑到文本和语义解析任务中,使用检索到的示例的效果如何?
主要发现
- IPT 与 PT 在所有五个任务上均优于 ICL,表明即使训练少量参数也有助于跨域任务。
- PT 与 IPT 之间没有普遍的胜者;性能取决于任务与配置(例如提示嵌入的数量)。
- 当上下文示例与测试输入高度相似时,IPT 的表现优于 PT(特别是在 ToTTo 中)。
- 随着可调参数数量增加,PT 表现出较高方差;而 IPT 降低了方差,对提示标记数量的敏感性较低。
- 在与目标任务演示配对时,源任务学习的软提示可以对新目标任务产生积极迁移,在某些跨任务设置中优于 ICL。
- IPT 通常在超参数上提供更稳定的收敛和鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。