[论文解读] Improving Retrieval for RAG based Question Answering Models on Financial Documents
本论文分析标准 RAG 流水线在金融文档中的局限性,并提出提高检索质量的技术,包括更先进的分块、查询扩展(HyDE)、元数据注释、重新排序以及嵌入微调。
The effectiveness of Large Language Models (LLMs) in generating accurate responses relies heavily on the quality of input provided, particularly when employing Retrieval Augmented Generation (RAG) techniques. RAG enhances LLMs by sourcing the most relevant text chunk(s) to base queries upon. Despite the significant advancements in LLMs' response quality in recent years, users may still encounter inaccuracies or irrelevant answers; these issues often stem from suboptimal text chunk retrieval by RAG rather than the inherent capabilities of LLMs. To augment the efficacy of LLMs, it is crucial to refine the RAG process. This paper explores the existing constraints of RAG pipelines and introduces methodologies for enhancing text retrieval. It delves into strategies such as sophisticated chunking techniques, query expansion, the incorporation of metadata annotations, the application of re-ranking algorithms, and the fine-tuning of embedding algorithms. Implementing these approaches can substantially improve the retrieval quality, thereby elevating the overall performance and reliability of LLMs in processing and responding to queries.
研究动机与目标
- 识别当前 RAG 流水线在领域特定(金融)问答任务中的局限性。
- 提出并评估检索增强方法,以提高上下文质量和答案准确性。
- 演示在金融聚焦的问答中减少幻觉并提升可靠性的技术。
提出的方法
- 批判性地评估 RAG 流水线中统一分块和基于余弦相似度的检索的局限性。
- 提出自适应分块策略(按文档结构如标题和表格递归分段)。
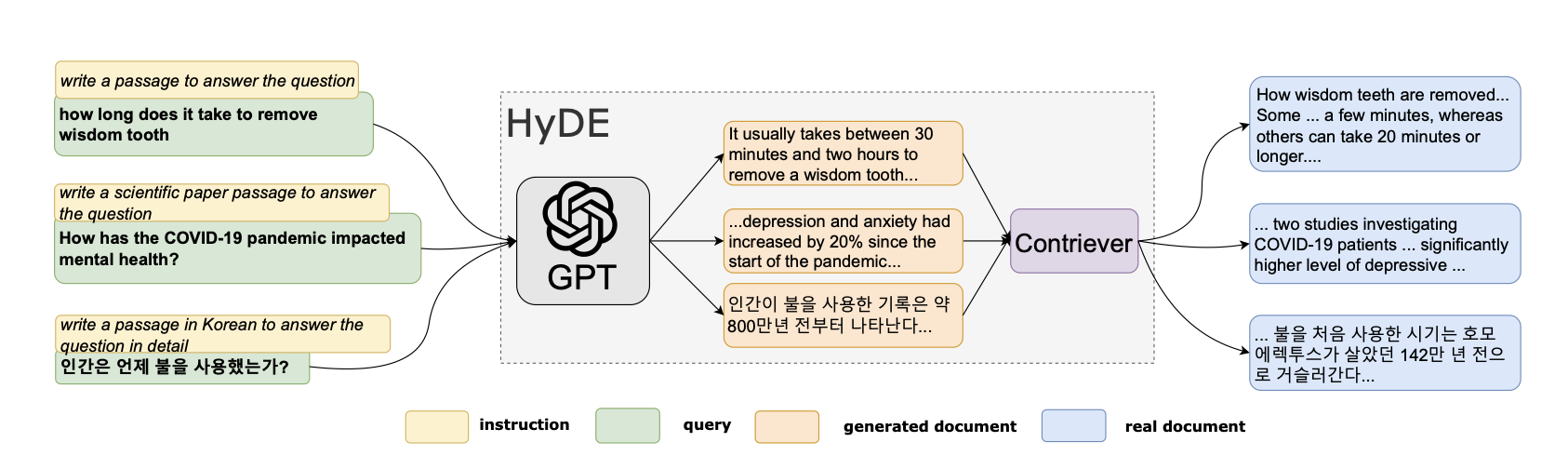
- 探索使用 Hypothetical Document Embeddings(HyDE)进行查询扩展,以改进检索引导。
- 引入元数据注释和逐文档索引,以保持文档身份和上下文。
- 应用重新排序算法以优先考虑真正相关的分块,而非仅仅相似的分块。
- 建议在领域特定数据上微调嵌入,以捕捉金融术语和细微差别。
实验结果
研究问题
- RQ1当前的 RAG 流水线在多文档金融问答任务中存在哪些不足?
- RQ2改进的检索策略(分块、HyDE、元数据、重新排序、领域特定嵌入)是否能提升金融文档中的答案质量与可靠性?
- RQ3在结构化金融数据集中,哪些评估策略最能准确体现检索质量与答案的忠实度?
主要发现
- 通过超越统一分块、采用文档结构感知分块,可以提升检索质量和答案的忠实度。
- HyDE 风格的查询扩展有助于定位超出用户原始问题的上下文,降低检索错误。
- 元数据注释减少跨文档混淆,提升在多个文档之间的上下文保持。
- 重新排序可以优先考虑上下文相关性,而不仅仅是相似性,从而提高所检索分块的质量。
- 在领域数据上的嵌入微调可以提升金融特定情境中的检索。
- FinanceBench(10-K、10-Q、8-K、盈利报告)为检索与问答性能的结构化评估提供基准。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。