[论文解读] Jasper: An End-to-End Convolutional Neural Acoustic Model
Jasper 是一个端到端的一维卷积神经声学模型,使用1D卷积、批归一化、ReLU、 dropout 和残差连接,在 Transformer-XL 语言模型和在 test-clean 上 2.95% 的 WER 下达到最先进的 LibriSpeech 结果。
In this paper, we report state-of-the-art results on LibriSpeech among end-to-end speech recognition models without any external training data. Our model, Jasper, uses only 1D convolutions, batch normalization, ReLU, dropout, and residual connections. To improve training, we further introduce a new layer-wise optimizer called NovoGrad. Through experiments, we demonstrate that the proposed deep architecture performs as well or better than more complex choices. Our deepest Jasper variant uses 54 convolutional layers. With this architecture, we achieve 2.95% WER using a beam-search decoder with an external neural language model and 3.86% WER with a greedy decoder on LibriSpeech test-clean. We also report competitive results on the Wall Street Journal and the Hub5'00 conversational evaluation datasets.
研究动机与目标
- 展示一种计算效率高的端到端 CNN ASR 声学模型,能够与 LibriSpeech 和其他基准的非端到端方法匹敌或超越。
- 研究架构选择(激活函数、归一化、残差)和优化器策略,以实现非常深的基于1D-CNN的 ASR 模型。
- 展示引入外部语言模型(神经型和 N-gram)对端到端 Jasper 性能的影响。
- 提出并评估残差连接的变体(包括 Dense Residual),以实现对非常深的网络的训练。
- 提供可复现实验设置和消融研究,使 Jasper 成为端到端 CNN 基于 ASR 的强基线。
提出的方法
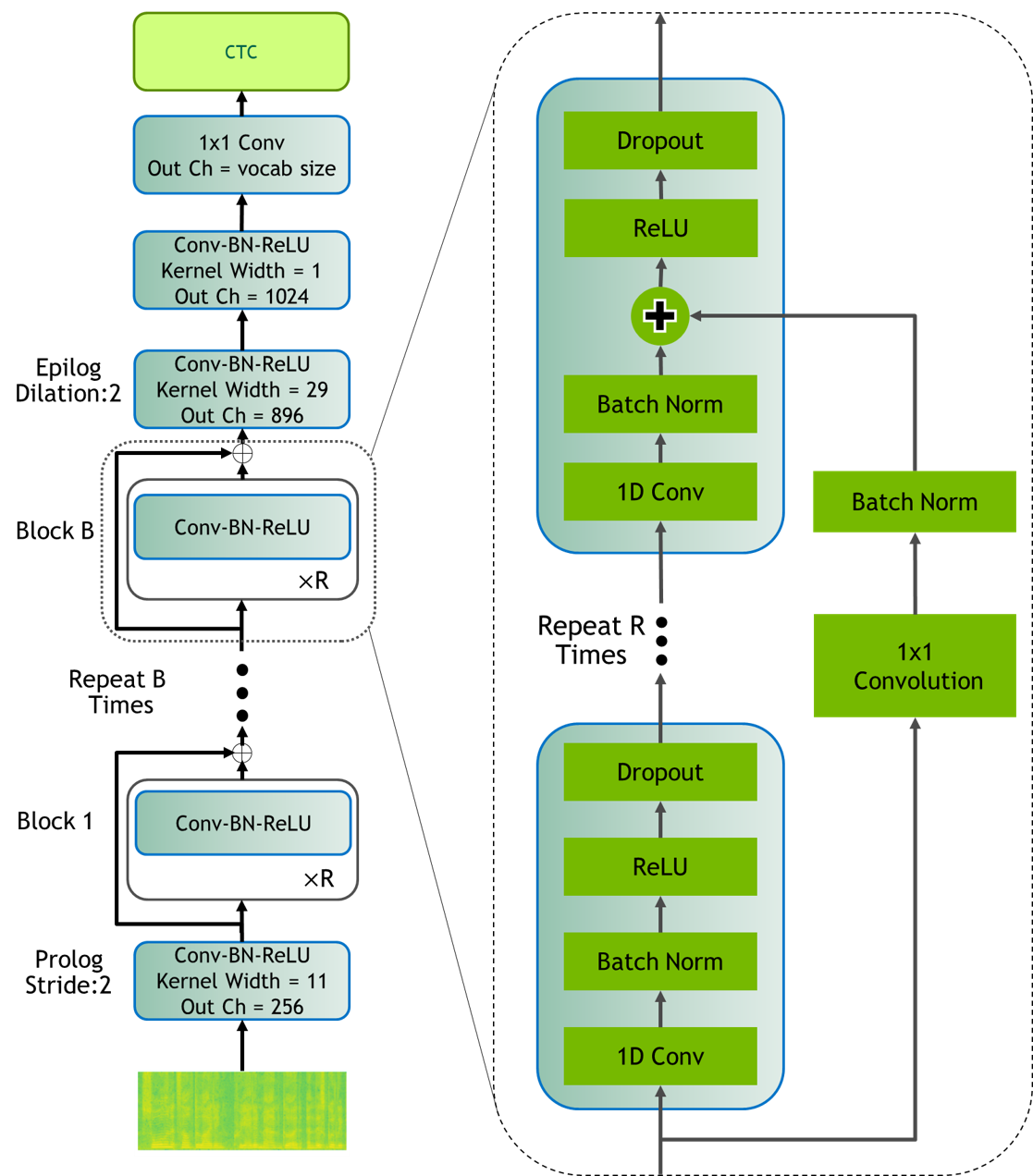
- 使用一组带残差连接的1D卷积块(Jasper B x R 模型)。
- 在归一化(批量归一化、层归一化、权重归一化)和激活函数(ReLU、cReLU、lReLU、GAU/GLU)上进行实验,以确定有效的组合。
- 引入 NovoGrad 优化器(分层次的二阶矩估计)以提高训练稳定性并减少内存。
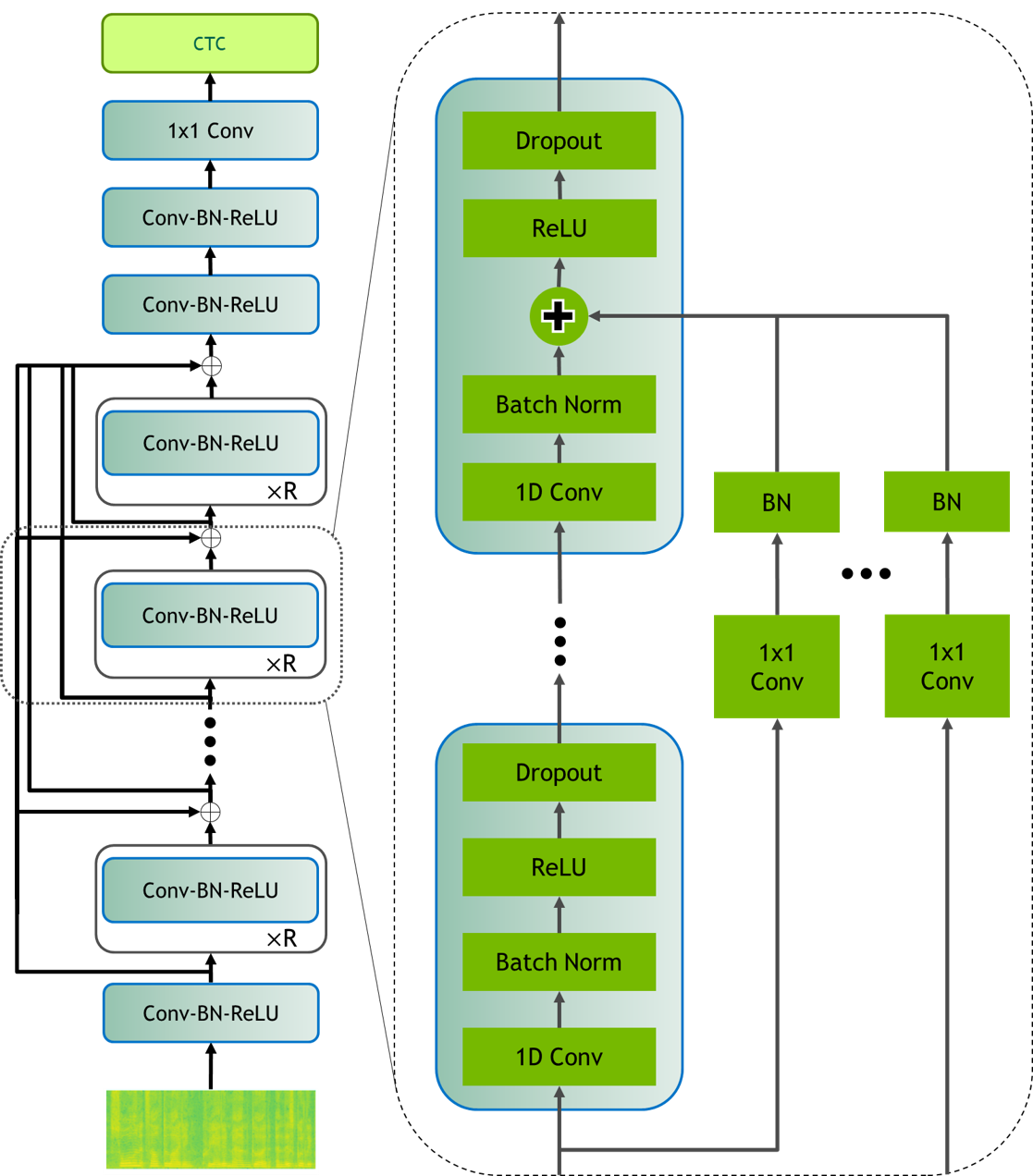
- 评估包括 Dense Residual 在内的残差拓扑,并将其与 DenseNet/DenseRNet 的块内连接进行比较;为更深的模型选择 Dense Residual。
- 使用束搜索解码(宽度2048)并结合声学+词级 N-gram LM,随后进行 Transformer-XL 神经语言模型重新评分;也报告贪婪解码结果。
- 训练 Jasper 的变体,最多54个卷积层(333M 参数),使用带冲量的 SGD 或 NovoGrad;在 LM 实验中应用类似 Spec 增强的掩蔽。
实验结果
研究问题
- RQ1仅由1D卷积组成的端到端声学模型在没有外部训练数据的情况下,是否能够在 LibriSpeech 上达到最先进的结果?
- RQ2哪种归一化、激活和残差连接配置最能支持非常深的1D CNN ASR模型?
- RQ3与 SGD 相比,NovoGrad 对训练稳定性和 WER 的影响是什么?
- RQ4将外部语言模型(N-gram 和 Transformer-XL)整合对 LibriSpeech 上的端到端 Jasper 性能有何影响?
- RQ5与经典残差相比, Dense Residual/DenseNet 风格的连接对深层 Jasper 模型是否具有优势?
主要发现
- Jasper 在 LibriSpeech test-clean 上取得端到端模型的 SOTA 结果,并在 test-other 上具有竞争力(在 test-clean 上使用 Transformer-XL LM 时 WER 为 2.95%)。
- 对于大型 Jasper 模型,带 ReLU 的批量归一化在归一化/激活组合中表现最好;残差连接对于非常深的网络的收敛是必要的。
- 在一个 10x5 的 Jasper DR 模型上,NovoGrad 将 LibriSpeech dev-clean 的 WER 从 4.00% 提升到 3.64%,显示出约9%的相对改进。
- Dense Residual 连接在性能上与其他密集/连接型方法相当,同时避免增长系数,使非常深的 Jasper 网络更易于训练。
- 在束搜索和重新评分中使用外部语言模型(N-gram 和 Transformer-XL)显著提高 LibriSpeech 的 WER,其中 Transformer-XL 为 Jasper DR 10x5 在 test-clean 实现 2.95% 的 WER。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。