[论文解读] Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
这篇论文系统性地研究了 LLM 作为 TriviaQA 的评审,与人类判断和词汇基线进行比较;它发现只有少数评审与人类高度一致,Cohen’s kappa 比百分比一致性更适合作为对齐度量,一些更便宜的方法在排名考试者模型方面可以媲美或超越。
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges, focusing on a clean scenario in which inter-human agreement is high. Investigating thirteen judge models of different model sizes and families, judging answers of nine different 'examtaker models' - both base and instruction-tuned - we find that only the best (and largest) models achieve reasonable alignment with humans. However, they are still quite far behind inter-human agreement and their assigned scores may still differ with up to 5 points from human-assigned scores. In terms of their ranking of the nine exam-taker models, instead, also smaller models and even the lexical metric contains may provide a reasonable signal. Through error analysis and other studies, we identify vulnerabilities in judge models, such as their sensitivity to prompt complexity and length, and a tendency toward leniency. The fact that even the best judges differ from humans in this comparatively simple setup suggest that caution may be wise when using judges in more complex setups. Lastly, our research rediscovers the importance of using alignment metrics beyond simple percent alignment, showing that judges with high percent agreement can still assign vastly different scores.
研究动机与目标
- 评估 LLM 评审与人类判断在知识基准(TriviaQA)上的对齐程度。
- 比较多种评审模型的大小和家族,包括基础模型和指令微调变体。
- 识别基于 LLM 的评审中的偏见、错误和可靠性问题。
- 评估更便宜或更专业的评审模型是否能够匹配或超越更大评审在对考试者模型排名中的表现。
提出的方法
- 使用包含 400 道题的 TriviaQA 验证集进行人工考试者注释;9 种评审模型对 9 种考试者模型进行评估。
- 将评审输出与人类判断进行比较,使用百分比一致性和 Cohen’s kappa。
- 基线词汇度量包括 exact match (EM) 和 contains match (contains)。
- 使用 Spearman’s rho 在九个考试者模型上计算与人类判断的排名相关性。
- 分析错误类型、提示变体效应,以及对虚假或幻觉回答的鲁棒性。
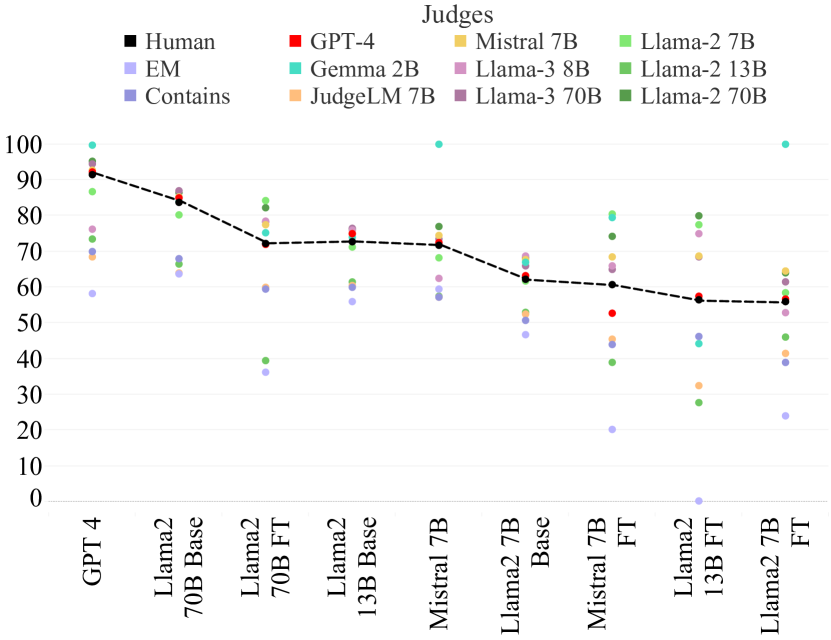
实验结果
研究问题
- RQ1不同的 LLM 作为评审在 TriviaQA 问题上的对齐程度有多好?
- RQ2Cohen’s kappa 是否为 LLM 评审提供比百分比一致性更可靠的对齐度量?
- RQ3哪些评审模型在对考试者模型的排名区分度上表现最好,代价(对齐度)的成本是多少?
- RQ4哪些系统性偏差或失效模式会影响 LLM 评审(例如提示长度、宽容度,或对非信息性回答的敏感性)?
主要发现
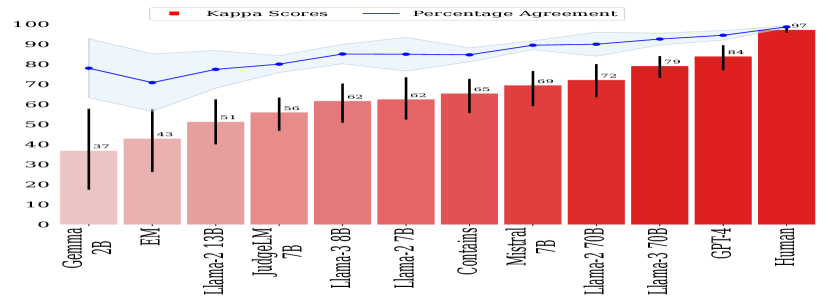
- GPT-4 Turbo 和 Llama-3 70B 显示出与人类高度一致的对齐度(kappa 分别为 84 和 79),但仍低于人类对齐水平(96)。
- Contains 相较于 EM 在若干评审上表现出更高的 kapp a,但 EM 通常整体表现最差;百分比一致性可能具有误导性。
- Contains、JudgeLM 7B、以及 GPT-4 Turbo/Llama-3 70B 在排名准确性上存在差异;某些更便宜的方法尽管对齐度较低,但在排名准确性上可以匹配或超过。
- 评审模型在遇到未充分指定或过于宽容的判断时通常表现较差,且可能被“Yes”或“Sure”等非信息性回答所愚弄。
- 当人类对齐度较高时,Recall 提升(r^2≈0.98),而 precision 与对齐度之间没有明确的趋势。
- 具有更详细指南的提示仅对表现最好的评审有帮助;许多评审对提示设计和引用顺序敏感。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。