[论文解读] Large Language Models Are Semi-Parametric Reinforcement Learning Agents
该论文提出 Rememberer,是一个可进化的基于 LLM 的代理,具有通过强化学习更新的持久外部经验记忆,能够实现半参数化 RL 而无需对 LLM 进行微调。它在 WebShop 和 WikiHow 基准测试中实现了最优结果。
Inspired by the insights in cognitive science with respect to human memory and reasoning mechanism, a novel evolvable LLM-based (Large Language Model) agent framework is proposed as REMEMBERER. By equipping the LLM with a long-term experience memory, REMEMBERER is capable of exploiting the experiences from the past episodes even for different task goals, which excels an LLM-based agent with fixed exemplars or equipped with a transient working memory. We further introduce Reinforcement Learning with Experience Memory (RLEM) to update the memory. Thus, the whole system can learn from the experiences of both success and failure, and evolve its capability without fine-tuning the parameters of the LLM. In this way, the proposed REMEMBERER constitutes a semi-parametric RL agent. Extensive experiments are conducted on two RL task sets to evaluate the proposed framework. The average results with different initialization and training sets exceed the prior SOTA by 4% and 2% for the success rate on two task sets and demonstrate the superiority and robustness of REMEMBERER.
研究动机与目标
- 推动使用长期经验记忆,使基于 LLM 的代理能够从超过固定样本的过去经历中学习。
- 提出 Experience Memory 的强化学习(RLEM),用于更新外部记忆,而非 LLM 参数。
- 设计 Rememberer,使其能够选择性地检索经历并为上下文学习提供动态范例。
- 在基准 RL 任务集 WebShop 和 WikiHow 上展示鲁棒性和性能提升。
提出的方法
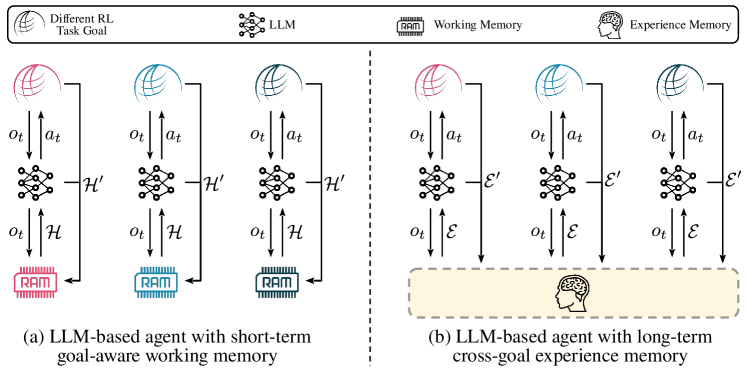
- 为 LLM 代理引入一个外部、持久的经历记忆,并定义它与环境的交互。
- 在记忆中使用类似 Bellman 的规则定义 Q 值更新,并为稳定性提供可选的 n-step bootstrapping。
- 使用记忆中的相似性检索来形成范例,通过少量示例提示引导 LLM。
- 呈现一个行动建议提示格式,包含被鼓励的和被不鼓励的行动,以利用记忆的经历。
- 通过 off-policy 学习更新记忆,而不对 LLM 参数进行微调。
- 在 WebShop 和 WikiHow 上评估 Rememberer,并与 State-of-the-Art 基线进行比较。
实验结果
研究问题
- RQ1一个基于 LLM 的代理是否可以在不对模型参数进行微调的情况下,从长期经验记忆中学习?
- RQ2相比固定示例或纯 RL/IL 基线,带外部记忆的半参数化 RL 框架是否在连续决策任务上提升性能?
- RQ3如何检索并向 LLM 呈现经验,以在各类任务中最大化决策质量?
- RQ4引导性与不鼓励性行动在记忆-范例提示中的引入对引导效果有何影响?
- RQ5Rememberer 对不同初始示例和训练集的鲁棒性如何?
主要发现
- Rememberer 在 WebShop 上超越了先前的 SOTA,Avg Score 0.68、Success Rate 0.39,分别高于 ReAct 的 0.66 和 0.36,以及 LLM-only 的 0.55 和 0.29。
- 在 WikiHow 上,Rememberer 实现 Avg Reward 2.63、Success Rate 0.93,优于 LLM-only 2.58/0.90 和 Mobile-Env 2.50/0.89。
- Rememberer 需要更少的带注释示例(例如 10 个任务共 74 步)即可达到强劲的性能,显著低于传统 RL/IL 方法。
- 消融实验表明,Bootstrap 提高了 reward 估计的准确性和最终性能,而去除观测相似性比去除任务相似性对结果的负面影响更大。
- 不鼓励行动的包含和两组件相似性(任务和观测)的引入显著影响性能,观测相似性尤为关键。
- 实验表明 Rememberer 对不同初始范例和训练集具有鲁棒性,在不同设定下仍能维持相对固定范例的改进。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。