[论文解读] Large Language Models for Compiler Optimization
一个从头开始训练的7B参数LLM,旨在优化LLVM汇编,学会选择编译器 passes 以最小化代码大小,在推理阶段不运行编译器实现了比编译器基线3.0%的指令数减少,并展示出强大的代码推理能力(91% 可编译,70% 与编译器输出的完全匹配)。
We explore the novel application of Large Language Models to code optimization. We present a 7B-parameter transformer model trained from scratch to optimize LLVM assembly for code size. The model takes as input unoptimized assembly and outputs a list of compiler options to best optimize the program. Crucially, during training, we ask the model to predict the instruction counts before and after optimization, and the optimized code itself. These auxiliary learning tasks significantly improve the optimization performance of the model and improve the model's depth of understanding. We evaluate on a large suite of test programs. Our approach achieves a 3.0% improvement in reducing instruction counts over the compiler, outperforming two state-of-the-art baselines that require thousands of compilations. Furthermore, the model shows surprisingly strong code reasoning abilities, generating compilable code 91% of the time and perfectly emulating the output of the compiler 70% of the time.
研究动机与目标
- Motivate exploration of LLMs for code optimization beyond generation and translation.
- Investigate whether an LLM can learn to select and apply compiler passes to minimize code size.
- Demonstrate auxiliary training tasks that improve optimization performance and understanding.
- Evaluate robustness across diverse unseen IR benchmarks.
提出的方法
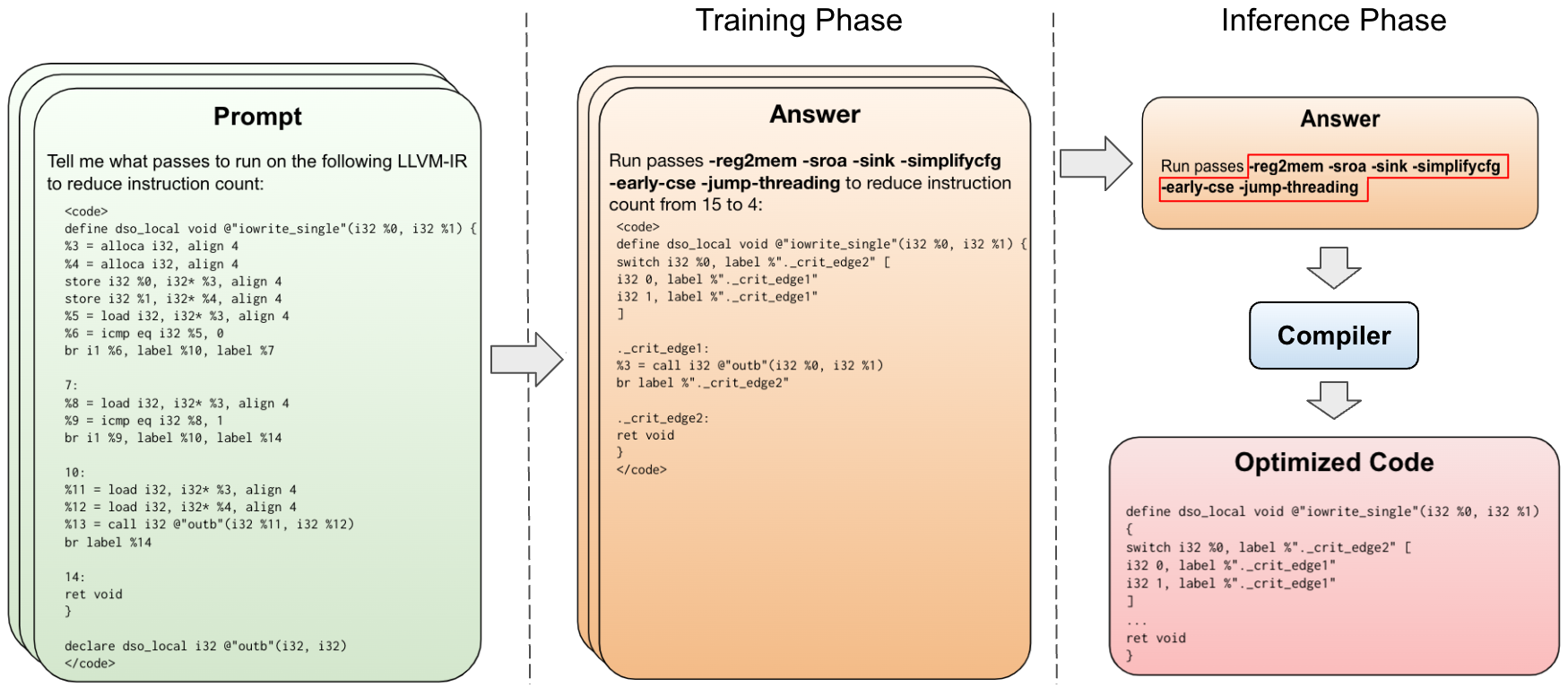
- Train a from-scratch 7B-parameter transformer (Llama 2 base) on millions of LLVM-IR examples paired with best compiler options and resulting optimized IR.
- Input: unoptimized LLVM-IR; output: a sequence of optimization passes (pass list) to apply via opt, with 122 passes and meta-flags considered.
- Auxiliary training tasks: predict instruction counts before and after optimization and generate the optimized IR, to deepen safety and understanding.
- Normalize LLVM-IR to reduce input length and standardize formatting for tokenization and learning.
- Use autotuning to obtain gold-standard pass lists per function, then broadcast across the training set as supervision.
- Train with 1,000,000 IR functions (training split) totaling ~373M tokens; optimize for code size as the evaluation metric.
- Evaluate on 100k unseen IR functions across multiple benchmark suites (AI-SOCO, ExeBench, POJ-104, Transcoder, CSmith, YARPGen).
实验结果
研究问题
- RQ1Can an LLM learn to predict an effective LLVM optimization pass list that minimizes instruction count for unseen code?
- RQ2Do auxiliary tasks (instruction-count prediction and generating optimized IR) improve the optimization performance of the model?
- RQ3How does an LLM-based pass-ordering approach compare to state-of-the-art ML baselines and autotuning in terms of instruction savings and code quality?
- RQ4What are the characteristics and limitations of model-generated code and pass lists across diverse benchmarks?
主要发现
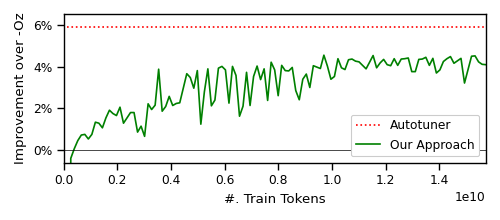
- The model achieves a 3.0% improvement in instruction-count reduction over the compiler baseline (-Oz) using a pass list produced entirely by the model (without compiler invocations at inference).
- The model yields a 91% compilable rate for model-generated optimized IR and a 70% exact-match rate to the compiler-generated optimized IR.
- BLEU score of 0.952 and 4.4% instruction reduction on the optimized code at peak, with the autotuner achieving 5.6% but requiring massive compilation effort.
- Across unseen benchmarks, the model outperforms -Oz, AutoPhase, and Coreset-NVP in overall improvement, and -Oz backup can prevent regressions while preserving gains.
- The model generalizes to longer or larger inputs (larger programs tend to yield bigger improvements) and can generate many novel pass lists not present in training data (105 such lists in 100k test programs).
- Ablation shows that training data size and also training the model to generate optimized code (not just pass lists) significantly affect downstream performance.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。