[论文解读] Large Language Models in the Clinic: A Comprehensive Benchmark
本文介绍 BenchHealth,一个医疗保健基准,评估 16 个 LLM 在医学推理、生成和理解方面,使用五个以信任为导向的评估指标和人工评估。
The adoption of large language models (LLMs) to assist clinicians has attracted remarkable attention. Existing works mainly adopt the close-ended question-answering (QA) task with answer options for evaluation. However, many clinical decisions involve answering open-ended questions without pre-set options. To better understand LLMs in the clinic, we construct a benchmark ClinicBench. We first collect eleven existing datasets covering diverse clinical language generation, understanding, and reasoning tasks. Furthermore, we construct six novel datasets and clinical tasks that are complex but common in real-world practice, e.g., open-ended decision-making, long document processing, and emerging drug analysis. We conduct an extensive evaluation of twenty-two LLMs under both zero-shot and few-shot settings. Finally, we invite medical experts to evaluate the clinical usefulness of LLMs. The benchmark data is available at https://github.com/AI-in-Health/ClinicBench.
研究动机与目标
- 通过超越封闭式问答,转向开放式医疗任务,激励在临床环境中可信赖地部署 LLMs。
- 在跨越推理、生成和理解的多样化医疗任务中,利用公开数据集对 LLM 进行基准测试。
- 引入额外的可靠性导向指标(faithfulness、comprehensiveness、robustness、generalizability)以及传统的匹配指标并行。
- 提供一般型与医学型 LLM,以及开源与商业模型之间的比较分析。
- 让医疗专家参与人类评估,以评估临床有用性和局限性。
提出的方法
- 使用七个任务和十三个公开数据集构建 BenchHealth,覆盖三个场景:医疗语言推理、生成与理解。
- 在零-shot 与 few-shot(1/3/5-shot)设置下评估 sixteen LLMs(nine general,seven medical)。
- 使用五个度量指标,超出准确性:faithfulness、comprehensiveness、robustness、generalizability,以及传统的匹配分数。
- 基于最前沿提示,针对每个任务纳入定制化提示以优化任务理解。
- 在患者对话场景中,邀请医疗专家进行人类评估,比较公开模型与领先商业 LLM 的表现。
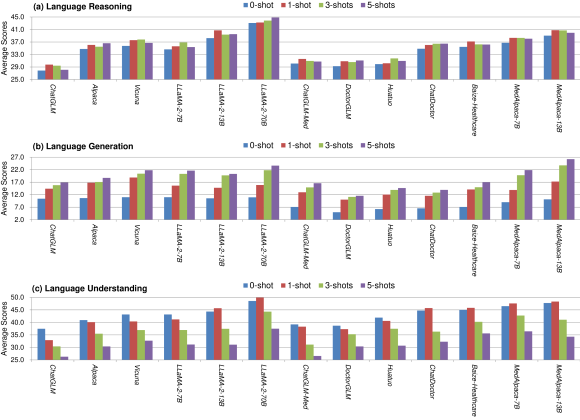
实验结果
研究问题
- RQ1开放式临床任务(推理、生成、理解)在 LLM 表现上与封闭式 QA 有何差异?
- RQ2商业化 LLM 是否在所有医疗任务中胜过开源模型,医学微调的 LLM 与通用 LLM 相比如何?
- RQ3模型规模、微调数据和少样本学习如何影响性能、可靠性和临床有用性?
- RQ4在临床环境中,哪些指标最能准确捕捉 faithfulness、comprehensiveness、robustness 与 generalizability?
- RQ5根据人类评估,一般型与医学型 LLM 的相对临床有用性如何?
主要发现
- 商业化 LLM(例如 GPT-4)在各项任务和数据集上优于开源模型。
- 所有 LLM 在封闭式 QA 上表现出色,但在开放式临床决策以及某些生成/理解任务上存在困难。
- 在医疗数据上对通用 LLM 进行微调可以提升推理/理解能力,但可能降低摘要能力。
- 更大参数量通常在各项任务上提升性能;few-shot 提升推理和生成,但可能影响理解。
- 医学 LLM 提供更忠实的答案和更好的泛化性,而通用 LLM 提供更广泛的完整性和鲁棒性。
- 人类评估显示医学 LLM 在 faithfulness 和 generalizability 上超越通用 LLM,但在 comprehensiveness 与 robustness 方面相较于通用 LLM 表现较弱。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。