[论文解读] Learning Delays in Spiking Neural Networks using Dilated Convolutions with Learnable Spacings
本文提出了一种离散时间反向传播方法,通过将延迟建模为带有可学习间距的一维时序卷积(DCLS),在深度前馈SNN中学习突触延迟,在时间基准SHD、SSC和GSC-35上实现最先进的结果,参数更少。
Spiking Neural Networks (SNNs) are a promising research direction for building power-efficient information processing systems, especially for temporal tasks such as speech recognition. In SNNs, delays refer to the time needed for one spike to travel from one neuron to another. These delays matter because they influence the spike arrival times, and it is well-known that spiking neurons respond more strongly to coincident input spikes. More formally, it has been shown theoretically that plastic delays greatly increase the expressivity in SNNs. Yet, efficient algorithms to learn these delays have been lacking. Here, we propose a new discrete-time algorithm that addresses this issue in deep feedforward SNNs using backpropagation, in an offline manner. To simulate delays between consecutive layers, we use 1D convolutions across time. The kernels contain only a few non-zero weights - one per synapse - whose positions correspond to the delays. These positions are learned together with the weights using the recently proposed Dilated Convolution with Learnable Spacings (DCLS). We evaluated our method on three datasets: the Spiking Heidelberg Dataset (SHD), the Spiking Speech Commands (SSC) and its non-spiking version Google Speech Commands v0.02 (GSC) benchmarks, which require detecting temporal patterns. We used feedforward SNNs with two or three hidden fully connected layers, and vanilla leaky integrate-and-fire neurons. We showed that fixed random delays help and that learning them helps even more. Furthermore, our method outperformed the state-of-the-art in the three datasets without using recurrent connections and with substantially fewer parameters. Our work demonstrates the potential of delay learning in developing accurate and precise models for temporal data processing. Our code is based on PyTorch / SpikingJelly and available at: https://github.com/Thvnvtos/SNN-delays
研究动机与目标
- 激发并利用脉冲神经网络中的延迟学习,以增强时间模式处理。
- 提出一种可微分方法,在深度SNN中将突触延迟与权重联合学习。
- 展示一维时序卷积与连接延迟之间的等价性,并使用DCLS来学习延迟。
- 在 SHD、SSC 和 GSC-35 上在没有循环连接的情况下,展示出更高的准确性且参数更少。
提出的方法
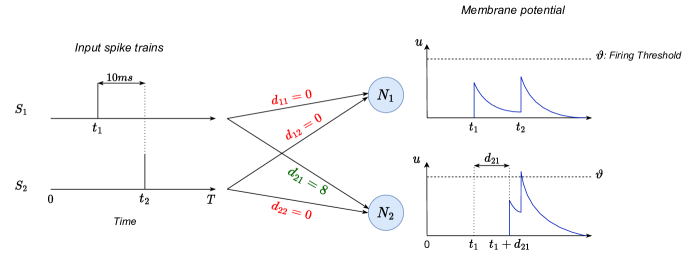
- 将每个突触延迟表述为一个包含每个突触仅一个非零元素的1D时序卷积核。
- 使用高斯插值的 DCLS 核来学习延迟位置,同时在训练期间逐步缩小高斯宽度(sigma)。
- 用可学习的位置 d_ij 和共享的 sigma 表示延迟,允许通过延迟参数进行反向传播。
- 将学习得到的连续卷积核转换为推理时的离散延迟,以实现稀疏、硬件友好的连接。
- 使用带泄漏积分与发放(Leaky Integrate-and-Fire)神经元和离线的前馈架构进行代理梯度反向传播的训练。
- 在 SHD、SSC 和 GSC-35 上,比较不同网络深度和参数数量下的最新方法。
实验结果
研究问题
- RQ1在深度前馈SNN中,延迟能否与突触权重一起通过反向传播学习?
- RQ2在时间脉冲模式基准上,学习延迟是否相对于固定或随机延迟具有显著的准确性提升?
- RQ3就性能和参数效率而言,DCLS-Delays 方法与密集延迟表示有何比较?
- RQ4在训练期间逐步收紧高斯核(sigma)对学习得到的延迟和整体准确性有何影响?
主要发现
| Dataset | Method | Rec. | Delays | #Params | Top1 Acc. |
|---|---|---|---|---|---|
| SHD | EventProp-GeNN | ✓ | ✕ | N/a | 84.80 ± 1.5% |
| SHD | Cuba-LIF | ✗ | ✕ | 0.14M | 87.80 ± 1.1% |
| SHD | Adaptive SRNN | ✓ | ✕ | N/a | 90.40% |
| SHD | SNN+Delays | ✗ | ✓ | 0.1M | 90.43% |
| SHD | TA-SNN | ✗ | ✕ | N/a | 91.08% |
| SHD | STSC-SNN | ✗ | ✕ | 2.1M | 92.36% |
| SHD | Adaptive Delays | ✗ | ✓ | 0.1M | 92.45% |
| SHD | DL128-SNN-Dloss | ✗ | ✓ | 0.14M | 92.56% |
| SHD | Dense Conv Delays (ours) | ✗ | ✓ | 2.7M | 93.44% |
| SHD | RadLIF | ✓ | ✕ | 3.9M | 94.62% |
| SHD | DCLS-Delays (2L-1KC) | ✗ | ✓ | 0.2M | 95.07 ± 0.24% |
| SHD | DCLS-Delays (2L-2KC) | ✗ | ✓ | 0.7M | 79.77 ± 0.09% |
| SHD | DCLS-Delays (3L-1KC) | ✗ | ✓ | 1.2M | 80.29 ± 0.06% |
| SHD | DCLS-Delays (3L-2KC) | ✗ | ✓ | 2.5M | 80.69 ± 0.21% |
| SSC | Recurrent SNN | ✓ | ✕ | N/a | 50.90 ± 1.1% |
| SSC | Heter. RSNN | ✓ | ✕ | N/a | 57.30% |
| SSC | SNN-CNN | ✗ | ✓ | N/a | 72.03% |
| SSC | Adaptive SRNN | ✓ | ✕ | N/a | 74.20% |
| SSC | SpikGRU | ✓ | ✕ | 0.28M | 77.00 ± 0.4% |
| SSC | RadLIF | ✓ | ✕ | 3.9M | 77.40% |
| SSC | Dense Conv Delays 2L | ✗ | ✓ | 10.9M | 77.86% |
| SSC | Dense Conv Delays 3L | ✗ | ✓ | 19M | 78.44% |
| SSC | DCLS-Delays (2L-1KC) | ✗ | ✓ | 0.7M | 79.77 ± 0.09% |
| SSC | DCLS-Delays (2L-2KC) | ✗ | ✓ | 1.4M | 80.16 ± 0.09% |
| SSC | DCLS-Delays (3L-1KC) | ✗ | ✓ | 1.2M | 80.29 ± 0.06% |
| SSC | DCLS-Delays (3L-2KC) | ✗ | ✓ | 2.5M | 80.69 ± 0.21% |
| GSC-35 | MSAT | ✗ | ✕ | N/a | 87.33% |
| GSC-35 | Dense Conv Delays 2L | ✗ | ✓ | 10.9M | 92.97% |
| GSC-35 | Dense Conv Delays 3L | ✗ | ✓ | 19M | 93.19% |
| GSC-35 | RadLIF | ✓ | ✕ | 1.2M | 94.51% |
| GSC-35 | DCLS-Delays (2L-1KC) | ✗ | ✓ | 0.7M | 94.91 ± 0.09% |
| GSC-35 | DCLS-Delays (2L-2KC) | ✗ | ✓ | 1.4M | 95.00 ± 0.06% |
| GSC-35 | DCLS-Delays (3L-1KC) | ✗ | ✓ | 1.2M | 95.29 ± 0.11% |
| GSC-35 | DCLS-Delays (3L-2KC) | ✗ | ✓ | 2.5M | 95.35 ± 0.04% |
- DCLS-Delays 在 2–3 个隐藏层时,在 SHD 上达到高达 95.07%,在 SSC 上达到 79.77–80.69%,在 GSC-35 上达到 94.91–95.35%,在各种配置下。
- 学习得到的延迟优于固定/随机延迟,尤其在稀疏连接场景下。
- 具有可学习间距的密集卷积延迟比标准密集延迟具有更高的准确性且使用更少的参数。
- 该方法在 SHD、SSC 和 GSC-35 上实现最先进的结果,且没有超出 LIF 内部递归的循环连接。
- 消融研究显示,联合学习权重和延迟并降低 sigma 相比恒定的 sigma 或固定延迟可提升性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。