[论文解读] Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
本文提出一种基于回归的去偏方法,用以消除 AlpacaEval 的长度偏差,产生 AlpacaEval-LC,使其与人类排名更一致,对冗长提示线索更鲁棒。
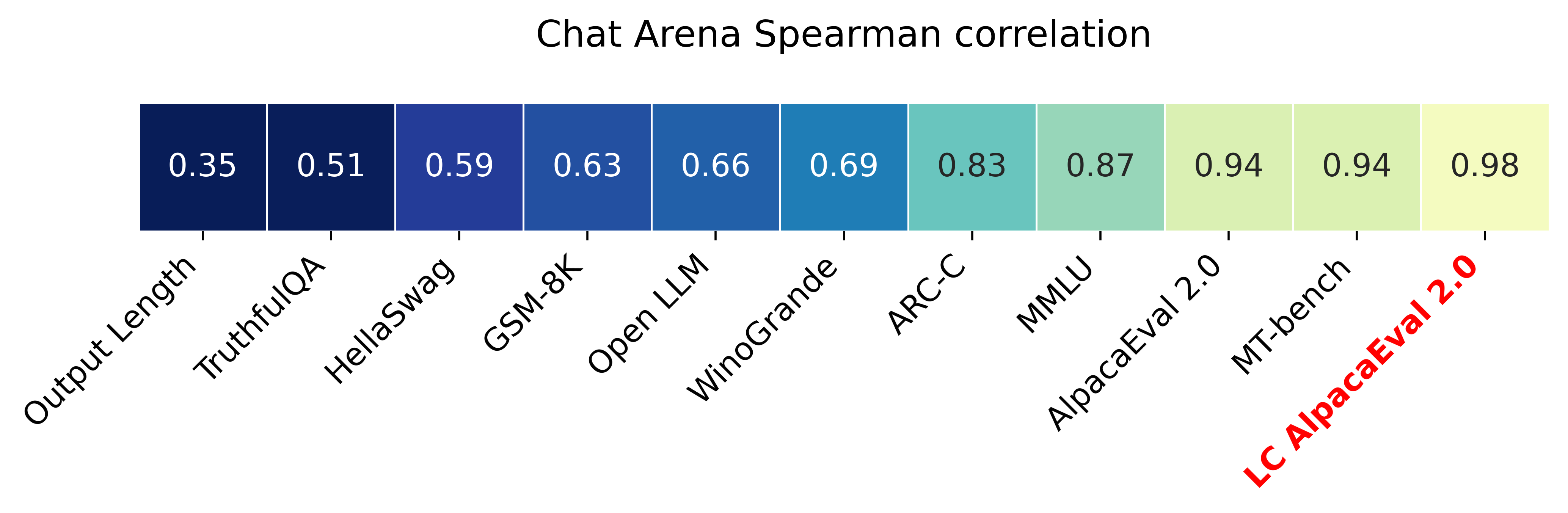
LLM-based auto-annotators have become a key component of the LLM development process due to their cost-effectiveness and scalability compared to human-based evaluation. However, these auto-annotators can introduce biases that are hard to remove. Even simple, known confounders such as preference for longer outputs remain in existing automated evaluation metrics. We propose a simple regression analysis approach for controlling biases in auto-evaluations. As a real case study, we focus on reducing the length bias of AlpacaEval, a fast and affordable benchmark for instruction-tuned LLMs that uses LLMs to estimate response quality. Despite being highly correlated with human preferences, AlpacaEval is known to favor models that generate longer outputs. We introduce a length-controlled AlpacaEval that aims to answer the counterfactual question: "What would the preference be if the model's and baseline's output had the same length?" To achieve this, we first fit a generalized linear model to predict the biased auto-annotator's preferences based on the mediators we want to control for (length difference) and other relevant features. We then obtain length-controlled preferences by predicting preferences while conditioning the GLM with a zero difference in lengths. Length-controlling not only improves the robustness of the metric to manipulations in model verbosity, but we also find that it increases the Spearman correlation with LMSYS Chatbot Arena from 0.94 to 0.98.
研究动机与目标
- 降低自动评估聊天大模型时的错误长度偏差。
- 提供一种简单、可解释的去偏方法,保留 AlpacaEval 的期望特性。
- 提升与人类判断(Chatbot Arena)的相关性,并对通过冗长变化进行的游戏化有鲁棒性。
- 提供一个可用于排行榜和 RLHF 场景的去偏、易于访问的评估框架。
提出的方法
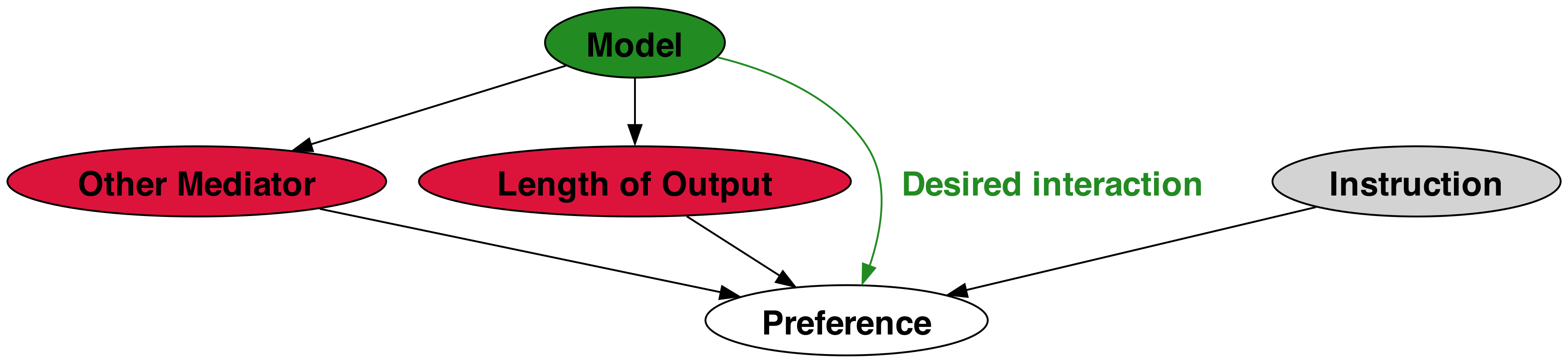
- 拟合广义线性模型以使用三要素预测自动评估偏好:模型身份、输出长度、任务难度。
- 使用带有长度项的逻辑回归,该长度项由规范长度差的双曲正切(tanh)表示,以捕捉收益递减。
- 通过去除长度项获得长度控制的胜率,得到一个対照性预估,即输出长度相等时的结果。
- 以带有交叉验证的 L2 正则化拟合 GLM,并对不同模型设定独立系数,确保在新增模型时的鲁棒性。
- 对长度耦合项进行温和正则化,以抵御对抗性截断攻击。
- 将 LC 胜率解释为具有直观对照性框架的标准胜率,并实现任意两家排行榜模型之间的成对预测。
实验结果
研究问题
- RQ1输出长度在多大程度上混淆了 AlpacaEval 的判断?
- RQ2是否可以用基于回归的去偏方法在保留模型身份和任务难度效应的同时去除与长度相关的方差?
- RQ3长度控制的 AlpacaEval(AlpacaEval-LC)是否比原始指标与人类评价(Chatbot Arena)的相关性更高?
- RQ4AlpacaEval-LC 对简单对抗性游戏如输出截断是否具鲁棒性?
主要发现
- 相对于原始 AlpacaEval,AlpacaEval-LC 降低了对基于长度的游戏性的敏感性。
- AlpacaEval-LC 将与 Chatbot Arena 的 Spearman 相关性从 0.94 提高到 0.98。
- 长度控制提高了在倾向于更短输出的专有模型的排行榜排名,而开源模型相对受到了惩罚。
- 基于 GLM 的去偏仍然可解释为一个胜率,并且可以预测排行榜基线之间的成对结果。
- 正则化在保持对标准模型的性能的同时減少了对抗性截断攻击。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。