[论文解读] Long-form factuality in large language models
该论文介绍 LongFact 用于长表述事实性基准测试, SAFE 作为使用 Google 搜索的自动化事实性评估器,以及一个新的基于 F1 的度量 F1@K,并在 4 个家族中对 38 个主题的 13 模型进行基准测试。
Large language models (LLMs) often generate content that contains factual errors when responding to fact-seeking prompts on open-ended topics. To benchmark a model's long-form factuality in open domains, we first use GPT-4 to generate LongFact, a prompt set comprising thousands of questions spanning 38 topics. We then propose that LLM agents can be used as automated evaluators for long-form factuality through a method which we call Search-Augmented Factuality Evaluator (SAFE). SAFE utilizes an LLM to break down a long-form response into a set of individual facts and to evaluate the accuracy of each fact using a multi-step reasoning process comprising sending search queries to Google Search and determining whether a fact is supported by the search results. Furthermore, we propose extending F1 score as an aggregated metric for long-form factuality. To do so, we balance the percentage of supported facts in a response (precision) with the percentage of provided facts relative to a hyperparameter representing a user's preferred response length (recall). Empirically, we demonstrate that LLM agents can outperform crowdsourced human annotators - on a set of ~16k individual facts, SAFE agrees with crowdsourced human annotators 72% of the time, and on a random subset of 100 disagreement cases, SAFE wins 76% of the time. At the same time, SAFE is more than 20 times cheaper than human annotators. We also benchmark thirteen language models on LongFact across four model families (Gemini, GPT, Claude, and PaLM-2), finding that larger language models generally achieve better long-form factuality. LongFact, SAFE, and all experimental code are available at https://github.com/google-deepmind/long-form-factuality.
研究动机与目标
- 提出 LongFact,一个覆盖 38 个主题的大规模长表述事实性提示集。
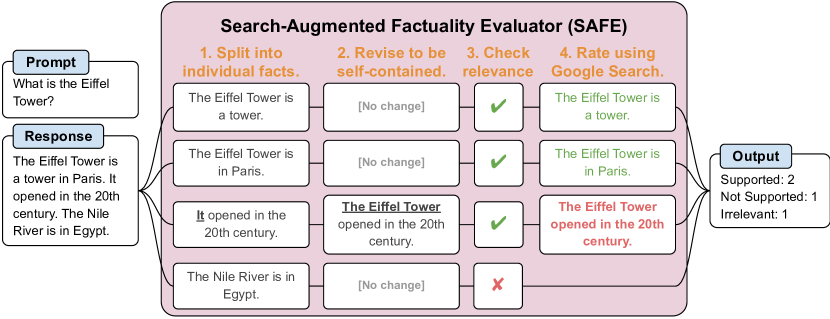
- 引入 SAFE,一个基于 LLM 的自动评估器,将回答分解为独立事实并通过 Google 搜索验证事实。
- 将 F1@K 定义为用于长表述事实性的一个带回忆率关注的聚合度量。
- 在四个家族中对 13 种模型进行基准测试,以评估规模效应对事实性的影响。
提出的方法
- 通过 GPT-4 生成 LongFact 提示,以覆盖横跨 38 个主题的长表述事实性问题(LongFact-Concepts 和 LongFact-Objects)。
- 开发 SAFE:一个将回答拆分为独立事实、评估相关性,并使用多步 Google 搜索推理将事实标注为 supported/not supported/irrelevant 的 LLM 代理。
- 用 F1@K 对事实性进行聚合,这是一个精确率-召回率的混合度量,其中召回率绑定到用户指定的理想长度 K。
- 在固定提示集合上使用 SAFE 对 13 种模型(Gemini、GPT、Claude、PaLM-2)进行基准测试,报告 F1@K 在 K=64 与 K=178 时的结果。
实验结果
研究问题
- RQ1大规模提示集(LongFact)在多样化主题上的长表述事实性探测能力有多强?
- RQ2相比人工标注,基于 LLM 的自动评估器(SAFE)能否可靠评估长表述的事实性?
- RQ3在主要家族(Gemini、GPT、Claude、PaLM-2)中,模型规模/架构如何影响长表述的事实性?
- RQ4通过超参数 K 引入召回分量是否提高了长表述回答的事实性指标的实用性?
主要发现
| 模型 | S (支持) | NS (不支持) | I (不相关) | 精确度 | R64 | R178 | F1@64 | F1@178 |
|---|---|---|---|---|---|---|---|---|
| Gemini-Ultra | 83.4 | 13.1 | 7.6 | 86.2 | 98.3 | 46.9 | 91.7 | 60.3 |
| Gemini-Pro | 66.6 | 12.1 | 5.5 | 82.0 | 88.5 | 37.4 | 83.7 | 50.4 |
| GPT-4-Turbo | 93.6 | 8.3 | 6.1 | 91.7 | 99.0 | 52.6 | 95.0 | 66.4 |
| GPT-4 | 59.1 | 7.0 | 2.4 | 89.4 | 88.3 | 33.2 | 88.0 | 48.0 |
| GPT-3.5-Turbo | 46.9 | 4.5 | 1.2 | 90.8 | 72.4 | 26.4 | 79.6 | 40.5 |
| Claude-3-Opus | 63.8 | 8.1 | 2.8 | 88.5 | 91.4 | 35.9 | 89.3 | 50.6 |
| Claude-3-Sonnet | 65.4 | 8.4 | 2.6 | 88.5 | 91.4 | 36.7 | 89.4 | 51.4 |
| Claude-3-Haiku | 39.8 | 2.8 | 1.3 | 92.8 | 62.0 | 22.4 | 73.5 | 35.8 |
| Claude-2.1 | 38.3 | 6.5 | 1.9 | 84.8 | 59.8 | 21.5 | 67.9 | 33.7 |
| Claude-2.0 | 38.5 | 6.3 | 1.3 | 85.5 | 60.0 | 21.6 | 68.7 | 34.0 |
| Claude-Instant | 43.9 | 8.1 | 1.3 | 84.4 | 68.4 | 24.6 | 73.8 | 37.6 |
| PaLM-2-L-IT-RLHF | 72.9 | 8.7 | 4.3 | 89.1 | 94.0 | 41.0 | 91.0 | 55.3 |
| PaLM-2-L-IT | 13.2 | 1.8 | 0.1 | 88.8 | 20.6 | 7.4 | 31.1 | 13.2 |
- LongFact 提供了跨越 38 个主题、包含 2,280 条提示的广泛长表述事实性基准。
- SAFE 在单个事实上的与人工标注一致率为 72%,在分歧案例中超过人工评估(在抽样子集中的正确率为 76%)。
- SAFE 的成本大约每次回答 0.19 美元,比群众外包人工标注便宜超过 20 倍。
- 在 13 种模型中,较大模型通常显示更高的长表述事实性,其中 GPT-4-Turbo、Gemini-Ultra、PaLM-2-L-IT-RLHF 在固定的 K 值下领先。
- F1@K 指标通过人类偏好的长度 K 来捕捉精确度和召回率,以一致地量化长表述事实性。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。