[论文解读] MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
MagicAnimate 通过扩散框架、时序建模与外观编码,生成时间一致、高保真的人体图像动画,受 DensePose 动作引导,在 TikTok 和 TED 演讲数据集上优于基线。
This paper studies the human image animation task, which aims to generate a video of a certain reference identity following a particular motion sequence. Existing animation works typically employ the frame-warping technique to animate the reference image towards the target motion. Despite achieving reasonable results, these approaches face challenges in maintaining temporal consistency throughout the animation due to the lack of temporal modeling and poor preservation of reference identity. In this work, we introduce MagicAnimate, a diffusion-based framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity. To achieve this, we first develop a video diffusion model to encode temporal information. Second, to maintain the appearance coherence across frames, we introduce a novel appearance encoder to retain the intricate details of the reference image. Leveraging these two innovations, we further employ a simple video fusion technique to encourage smooth transitions for long video animation. Empirical results demonstrate the superiority of our method over baseline approaches on two benchmarks. Notably, our approach outperforms the strongest baseline by over 38% in terms of video fidelity on the challenging TikTok dancing dataset. Code and model will be made available.
研究动机与目标
- 解决人体图像动画中的时间不一致性与参考外观保真度问题。
- 开发一个跨帧编码时间信息的视频扩散模型。
- 引入密集外观编码器以保留身份、服饰和背景细节。
- 通过简单的视频融合策略在重叠分段之上实现长视频动画。
- 通过图像-视频联合训练和分割感知条件化提升每帧保真度。
提出的方法
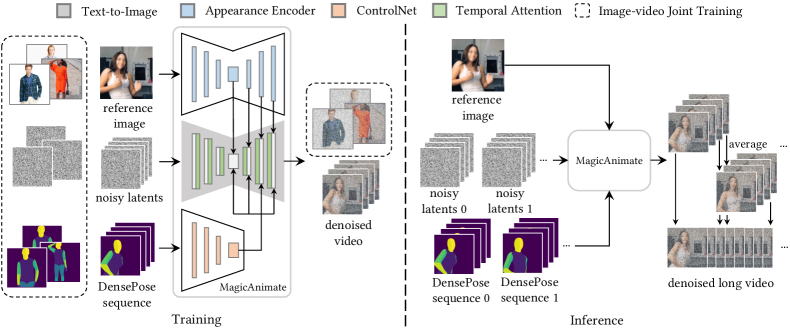
- 将扩散模型扩展到视频领域,通过在2D UNet 中扩展时间注意力块形成3D时序 UNet。
- 引入一个外观编码器,在去噪过程中将密集的参考图像特征注入到空间自注意力中,提升身份与背景保留。
- 通过姿态 ControlNet 对 DensePose 序列进行条件化,驱动运动转移。
- 对长视频进行分段逐步处理,采用滑动窗口重叠并对重叠帧进行平均以确保平滑过渡。
- 采用图像-视频联合训练策略,利用大规模图像数据集获得更丰富的外观线索并维持每帧保真度。
- 在推理阶段使用简单的视频融合技术,将重叠分段的输出融合以实现无缝长时序动画。

实验结果
研究问题
- RQ1扩散框架是否能超越逐帧方法在人体图像动画上的时间一致性?
- RQ2是否有专用外观编码器在身份保留和背景保真方面优于基于 CLIP 的外观条件化?
- RQ3时序注意力与图像-视频联合训练对每帧质量与视频保真度有何影响?
- RQ4在推理阶段使用简单的重叠视频融合对于长视频的流畅性有多大作用?
- RQ5MagicAnimate 在未知领域和多人物场景上的泛化能力如何?
主要发现
| Method | Image | Video | L1 | PSNR | SSIM | LPIPS | FID | FID-VID | FVD |
|---|---|---|---|---|---|---|---|---|---|
| TPS* | 3.23E-04 | 29.18 | 0.673 | 0.299 | 53.78 | 72.55 | 306.17 | ||
| MRAA* | 3.21E-04 | 29.39 | 0.672 | 0.296 | 54.47 | 66.36 | 284.82 | ||
| TPS | 6.17E-04 | 28.17 | 0.560 | 0.449 | 140.37 | 142.52 | 800.77 | ||
| MRAA | 4.61E-04 | 28.39 | 0.646 | 0.337 | 85.49 | 71.97 | 468.66 | ||
| IPA+CtrlN | 7.38E-04 | 28.03 | 0.459 | 0.481 | 69.83 | 113.31 | 802.44 | ||
| IPA+CtrlN-V | 6.99E-04 | 28.00 | 0.479 | 0.461 | 66.81 | 86.33 | 666.27 | ||
| DisCo | 3.78E-04 | 29.03 | 0.668 | 0.292 | 30.75 | 59.90 | 292.80 | ||
| MagicAnimate (Ours) | 3.13E-04 | 29.16 | 0.714 | 0.239 | 32.09 | 21.75 | 179.07 |
- MagicAnimate 在 TikTok 与 TED 演讲数据集的图像与视频保真度指标上达到了行业前沿水平。
- 在 TikTok 上,MagicAnimate 在视频质量(FVD)方面比最强基线高出超过38%,在 FID-VID 方面也提升约38%。
- 在 TED 演讲数据集上达到最佳的 FID-VID 与 FVD,并显著优于基线。
- 消融结果显示时序建模与外观编码器显著提升了 SSIM 和 LPIPS,图像-视频联合训练提升了整体保真度。
- 简单的视频融合策略为长视频带来更平滑的过渡并提升时间的一致性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。