[论文解读] Medical Graph RAG: Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation
MedGraphRAG 引入一个基于图的检索增强生成管线,用于医疗领域的语言模型,通过构建分层医疗知识图谱和U-retrieve检索策略,实现有据可查、带来源引用且更安全的回答。
We introduce a novel graph-based Retrieval-Augmented Generation (RAG) framework specifically designed for the medical domain, called extbf{MedGraphRAG}, aimed at enhancing Large Language Model (LLM) capabilities for generating evidence-based medical responses, thereby improving safety and reliability when handling private medical data. Graph-based RAG (GraphRAG) leverages LLMs to organize RAG data into graphs, showing strong potential for gaining holistic insights from long-form documents. However, its standard implementation is overly complex for general use and lacks the ability to generate evidence-based responses, limiting its effectiveness in the medical field. To extend the capabilities of GraphRAG to the medical domain, we propose unique Triple Graph Construction and U-Retrieval techniques over it. In our graph construction, we create a triple-linked structure that connects user documents to credible medical sources and controlled vocabularies. In the retrieval process, we propose U-Retrieval which combines Top-down Precise Retrieval with Bottom-up Response Refinement to balance global context awareness with precise indexing. These effort enable both source information retrieval and comprehensive response generation. Our approach is validated on 9 medical Q\&A benchmarks, 2 health fact-checking benchmarks, and one collected dataset testing long-form generation. The results show that MedGraphRAG consistently outperforms state-of-the-art models across all benchmarks, while also ensuring that responses include credible source documentation and definitions. Our code is released at: https://github.com/MedicineToken/Medical-Graph-RAG.
研究动机与目标
- 解决医疗领域语言模型产生幻觉的风险,使回答以可验证的医疗来源为依据。
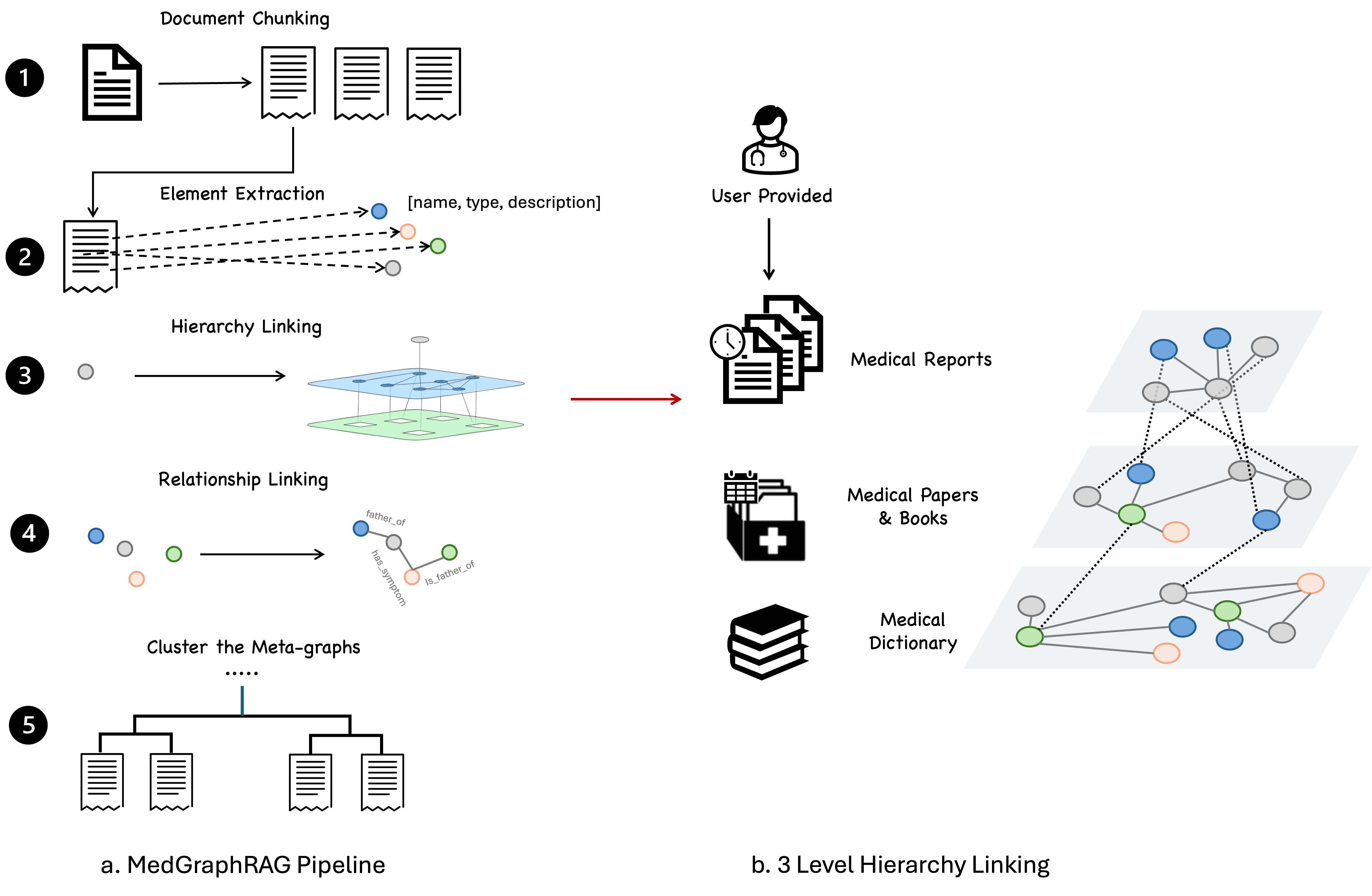
- 开发一个三层级的分层图,将用户数据、医学文献和 UMLS 词汇整合。
- 实现一个检索机制(U-retrieve),在全局上下文与对相关图段的高效访问之间取得平衡。
- 证明 MedGraphRAG 在不进行额外模型微调的情况下提升医疗问答基准。
- 展示为临床问题提供循证、基于来源的解释的能力。
提出的方法
- Segment medical documents using a hybrid static-semantic chunking approach to capture context.
- Extract entities from chunks and build a three-level graph: user documents, foundational medical books/papers, and UMLS-based terms.
- Link entities into meta-graphs and merge them into a global graph based on semantic similarity.
- Construct meta-graphs per data chunk and use U-retrieve to top-downly and bottom-up generate responses with source citations.
实验结果
研究问题
- RQ1Can a three-tier hierarchical medical graph improve accuracy and reliability of LLM-generated medical answers without fine-tuning?
- RQ2Does integrating user data, medical literature, and UMLS-grounded terms reduce hallucinations and improve grounding of medical assertions?
- RQ3How does U-retrieve compare to other retrieval strategies in terms of retrieval accuracy and response quality?
- RQ4What is the impact of hierarchical graph construction and advanced chunking on medical QA benchmarks?
- RQ5Do MedGraphRAG outputs provide verifiable source-based explanations suitable for clinical use?
主要发现
| 模型 | 大小 | 开源 | MedQA | MedMCQA | PubMedQA |
|---|---|---|---|---|---|
| LLaMA2 | 13B | yes | 42.7 | 37.4 | 68.0 |
| LLaMA2-MedGraphRAG | 13B | yes | 65.5 | 51.4 | 73.2 |
| LLaMA2 | 70B | yes | 43.7 | 35.0 | 74.3 |
| LLaMA2-MedGraphRAG | 70B | yes | 69.2 | 58.7 | 76.0 |
| LLaMA3 | 8B | yes | 59.8 | 57.3 | 75.2 |
| LLaMA3-MedGraphRAG | 8B | yes | 74.2 | 61.6 | 77.8 |
| LLaMA3 | 70B | yes | 72.1 | 65.5 | 77.5 |
| LLaMA3-MedGraphRAG | 70B | yes | 88.4 | 79.1 | 83.8 |
| Gemini-pro | - | no | 59.0 | 54.8 | 69.8 |
| Gemini-MedGraphRAG | - | no | 72.6 | 62.0 | 76.2 |
| GPT-4 | - | no | 81.7 | 72.4 | 75.2 |
| GPT-4 MedGraphRAG | - | no | 91.3 | 81.5 | 83.3 |
| Human (expert) | - | - | 87.0 | 90.0 | 78.0 |
- MedGraphRAG significantly improves multiple medical QA benchmarks across various models (e.g., MedQA, MedMCQA, PubMedQA).
- Smaller LLMs (e.g., LLaMA2-13B, LLaMA3-8B) gain notable gains, widening applicability beyond large models.
- On GPT-4, MedGraphRAG achieves state-of-the-art results on MedQA and surpasses several fine-tuned baselines.
- Responses include grounded citations and explanations of medical terms, enhancing reliability and interpretability.
- Ablation studies show hybrid semantic chunking, hierarchical graph construction, and U-retrieve contribute to performance gains.

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。