[论文解读] MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
MedNeXt 提出了一种完全 ConvNeXt 3D 编码器-解码器架构,带有残差反向瓶颈和 UpKern 内核上采样,在 CT 和 MRI 数据集上实现了对医学影像分割的最新性能。
There has been exploding interest in embracing Transformer-based architectures for medical image segmentation. However, the lack of large-scale annotated medical datasets make achieving performances equivalent to those in natural images challenging. Convolutional networks, in contrast, have higher inductive biases and consequently, are easily trainable to high performance. Recently, the ConvNeXt architecture attempted to modernize the standard ConvNet by mirroring Transformer blocks. In this work, we improve upon this to design a modernized and scalable convolutional architecture customized to challenges of data-scarce medical settings. We introduce MedNeXt, a Transformer-inspired large kernel segmentation network which introduces - 1) A fully ConvNeXt 3D Encoder-Decoder Network for medical image segmentation, 2) Residual ConvNeXt up and downsampling blocks to preserve semantic richness across scales, 3) A novel technique to iteratively increase kernel sizes by upsampling small kernel networks, to prevent performance saturation on limited medical data, 4) Compound scaling at multiple levels (depth, width, kernel size) of MedNeXt. This leads to state-of-the-art performance on 4 tasks on CT and MRI modalities and varying dataset sizes, representing a modernized deep architecture for medical image segmentation. Our code is made publicly available at: https://github.com/MIC-DKFZ/MedNeXt.
研究动机与目标
- 证明一个完全面向 ConvNeXt 3D 的编码器–解码器在数据稀缺条件下能够超过基于 Transformer 的和大内核基线的医学图像分割性能。
- 引入残差反向瓶颈用于上采样/下采样,以在各尺度之间保持语义丰富性。
- 开发 UpKern,一种基于三线性上采样的初始化技术,在有限数据条件下缓解大内核训练饱和。
- 在深度、宽度和感受野之间进行复合缩放,以优化不同任务和模态的性能。
提出的方法
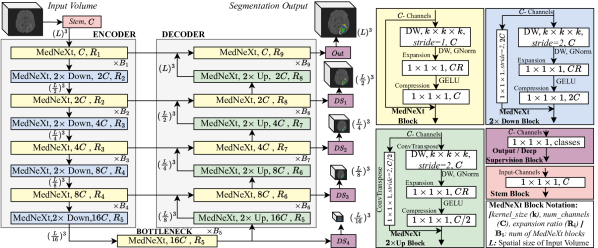
- 使用仅由 ConvNeXt 模块组成的 4 层编码器-解码器 MedNeXt 架构。
- 在上采样/下采样路径中实现残差反向瓶颈,以改善梯度流动和语义保留。
- 引入 UpKern:基于三线性上采样的初始化,在不从零重新训练的情况下扩展内核大小。
- 采用复合缩放,在 MedNeXt 配置(S、B、M、L)中联合缩放深度、宽度和内核大小。
- 在四个数据集上进行 5 折交叉验证训练,并与 nnUNet 及多种 Transformer/大内核基线进行比较。
实验结果
研究问题
- RQ1一个完全 ConvNeXt 3D 的分割网络在数据有限的医学影像任务中是否能够超过基于 Transformer 的方法和大内核方法?
- RQ2残差反向瓶颈和 UpKern 初始化是否提高医学分割中大内核的性能和训练稳定性?
- RQ3在 CT 和 MRI 数据集规模各异的情况下,深度、宽度和感受野的复合缩放是否能够带来一致的收益?
主要发现
| 网络 | BTCV DSC | BTCV SDC | AMOS22 DSC | AMOS22 SDC | KiTS19 DSC | KiTS19 SDC | BraTS21 DSC | BraTS21 SDC | AVG DSC | AVG SDC |
|---|---|---|---|---|---|---|---|---|---|---|
| nnUNet Baselines | 83.56 | 86.07 | 88.88 | 91.70 | 89.88 | 86.88 | 91.23 | 90.46 | 88.39 | 88.78 |
| UNETR | 75.06 | 75.00 | 81.98 | 82.65 | 84.10 | 78.05 | 89.65 | 88.28 | 82.36 | 81.00 |
| TransUNet | 76.72 | 76.64 | 85.05 | 86.52 | 80.82 | 72.90 | 89.17 | 87.78 | 82.94 | 80.96 |
| TransBTS | 82.35 | 84.33 | 86.52 | 88.84 | 87.03 | 83.53 | 90.66 | 89.71 | 86.64 | 86.60 |
| nnFormer | 80.76 | 82.37 | 84.20 | 86.38 | 89.09 | 85.08 | 90.42 | 89.83 | 86.12 | 85.92 |
| SwinUNETR | 80.95 | 82.43 | 86.83 | 89.23 | 87.36 | 83.09 | 90.48 | 89.56 | 86.41 | 86.08 |
| 3D-UX-Net | 80.76 | 82.30 | 87.28 | 89.74 | 88.39 | 84.03 | 90.63 | 89.63 | 86.77 | 86.43 |
| MedNeXt-S kernel:3 | 83.90 | 86.60 | 89.03 | 91.97 | 90.45 | 87.80 | 91.27 | 90.46 | 88.66 | 89.21 |
| MedNeXt-B | 84.01 | 86.77 | 89.14 | 92.10 | 91.02 | 88.24 | 91.30 | 90.51 | 88.87 | 89.41 |
| MedNeXt-M | 84.31 | 87.34 | 89.27 | 92.28 | 90.78 | 88.22 | 91.57 | 90.78 | 88.98 | 89.66 |
| MedNeXt-L | 84.57 | 87.54 | 89.58 | 92.62 | 90.61 | 88.08 | 91.57 | 90.81 | 89.08 | 89.76 |
| MedNeXt-S kernel:5 | 83.92 | 86.80 | 89.27 | 92.26 | 90.08 | 87.04 | 91.40 | 90.57 | 88.67 | 89.17 |
| MedNeXt-B | 84.23 | 87.06 | 89.38 | 92.36 | 90.30 | 87.40 | 91.48 | 90.70 | 88.85 | 89.38 |
| MedNeXt-M | 84.41 | 87.48 | 89.58 | 92.65 | 90.87 | 88.15 | 91.49 | 90.67 | 89.09 | 89.74 |
| MedNeXt-L | 84.82 | 87.85 | 89.87 | 92.95 | 90.71 | 87.85 | 91.46 | 90.73 | 89.22 | 89.85 |
- 相比基线,MedNeXt 变体在四个数据集(BTCV、AMOS22、KiTS19、BraTS21)上取得了最先进的性能。
- MedNeXt-L 采用内核 5×5×5 与 UpKern 初始化,在公开测试集上超越 nnUNet(DSC 分数;BTCV 88.76,AMOS22 91.77,KiTS19 91.02,BraTS21 88.01)。
- 消融研究显示,残差反向瓶颈显著提升了相对于标准重采样的性能。
- UpKern 初始化使大内核网络(5×5×5)能够超越小内核模型;从头开始用大内核进行训练则效果不佳。
- 在深度、宽度和内核大小上的复合缩放在各数据集上带来进一步提升。
- 在 5 折交叉验证中,3×3×3 或 5×5×5 内核的 MedNeXt 变体在所有数据集上都优于所有基线。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。