[论文解读] Mistral 7B
简述:Mistral 7B 是一个具有分组查询注意力和滑动窗口注意力的 7B 语言模型,在多个基准测试中优于开放/开源权重基线,并包含一个指令微调变体。
We introduce Mistral 7B v0.1, a 7-billion-parameter language model engineered for superior performance and efficiency. Mistral 7B outperforms Llama 2 13B across all evaluated benchmarks, and Llama 1 34B in reasoning, mathematics, and code generation. Our model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a reduced inference cost. We also provide a model fine-tuned to follow instructions, Mistral 7B -- Instruct, that surpasses the Llama 2 13B -- Chat model both on human and automated benchmarks. Our models are released under the Apache 2.0 license.
研究动机与目标
- 证明一个小型、高效设计的 7B 模型能够在广泛的基准测试中超越更大规模的开放模型。
- 引入架构创新(分组查询注意力和滑动窗口注意力)以提升推理速度和序列处理能力。
- 提供一个指令微调变体并展示其相对于更大聊天模型的竞争力。
- 展示面向实际应用的部署工具以及防护与内容审核能力。
提出的方法
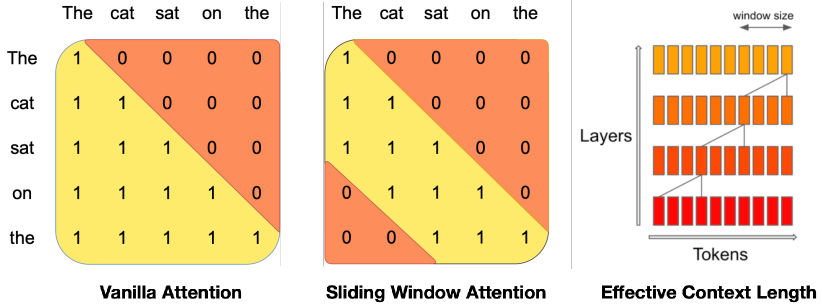
- 采用分组查询注意力(GQA)以加速推断并在解码期间降低内存占用。
- 使用滑动窗口注意力(SWA)以在较低成本下扩展有效上下文长度。
- 实现滚动缓冲缓存以限制解码时的内存使用。
- 预填充并对长提示进行分块以在生成过程中管理注意力与缓存。
- 在指令数据集上对模型的一个版本进行微调,以创建 Mistral 7B – Instruct。
- 发布参考实现及与 vLLM、Skypilot、Hugging Face 的集成。
实验结果
研究问题
- RQ1一个 7B 模型是否能够在包括推理、数学与代码生成在内的多样化基准测试中超越更大规模的开放模型(7B/13B/34B)?
- RQ2架构创新(GQA + SWA)是否在不牺牲性能的前提下提供实际的加速和内存节省?
- RQ3在聊天类基准中,基础 7B 模型与指令微调变体之间的性能差距是多少?
- RQ4在与轻量级模型部署时,防护边界和内容审核能力如何发挥作用?
- RQ5在聊天和指令跟随设置中,Mistral 7B 相较于现有的开放模型表现如何?
主要发现
| 模型 | 模态 | MMLU | Hellaswag | WinoG | PIQA | Arc-e | Arc-c | NQ | TriviaQA | HumanEval | MBPP | MATH | GSM8K |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA 2 7B | Pretrained | 44.4% | 77.1% | 69.5% | 77.9% | 68.7% | 43.2% | 24.7% | 63.8% | 11.6% | 26.1% | 3.9% | 16.0% |
| LLaMA 2 13B | Pretrained | 55.6% | 80.7% | 72.9% | 80.8% | 75.2% | 48.8% | 29.0% | 69.6% | 18.9% | 35.4% | 6.0% | 34.3% |
| Code-Llama 7B | Finetuned | 36.9% | 62.9% | 62.3% | 72.8% | 59.4% | 34.5% | 11.0% | 34.9% | 31.1% | 52.5% | 5.2% | 20.8% |
| Mistral 7B | Pretrained | 60.1% | 81.3% | 75.3% | 83.0% | 80.0% | 55.5% | 28.8% | 69.9% | 30.5% | 47.5% | 13.1% | 52.2% |
- Mistral 7B 在所有评估基准上都优于 Llama 2 13B。
- 在数学与代码生成基准中也超越 Llama 1 34B。
- Mistral 7B – Instruct 聊天模型超越 Llama 2 13B – Chat,并且接近 13B 聊天模型的性能。
- 高效的注意力机制(GQA 和 SWA)实现更快的推断和更长的有效上下文,同时降低内存使用。
- 防护边界与系统提示可以引导输出,系统提示提升安全性并保持实用性。
- 自我反思内容审核实现了高准确率(99.4%)和鲁棒召回率(95.6%)。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。