[论文解读] MoE-Infinity: Efficient MoE Inference on Personal Machines with Sparsity-Aware Expert Cache
MoE-Infinity 引入 activation-aware Expert offloading,用于 mixture-of-experts serving,使用 sequence-level expert activation traces 以实现有针对性的 prefetching 和 caching,降低延迟与部署成本。
This paper presents MoE-Infinity, an efficient MoE inference system designed for personal machines with limited GPU memory capacity. The key idea for MoE-Infinity is that on personal machines, which are often single-user environments, MoE-based LLMs typically operate with a batch size of one. In this setting, MoE models exhibit a high degree of activation sparsity, meaning a small number of experts are frequently reused in generating tokens during the decode phase. Leveraging this idea, we design a sparsity-aware expert cache, which can trace the sparse activation of experts during inference and carefully select the trace that represents the sparsity pattern. By analyzing these selected traces, MoE-Infinity guides the replacement and prefetching of the expert cache, providing 3.1-16.7x per-token latency improvements over numerous state-of-the-art systems, including vLLM, Ollama, DeepSpeed and BrainStorm across various MoE models (DeepSeek and Mixtral) when handling different LLM tasks. MoE-Infinity's source code is publicly available at https://github.com/EfficientMoE/MoE-Infinity
研究动机与目标
- 在成本受限的环境中,推动降低用于服务大型 MoE 模型的内存和延迟成本。
- 提出 activation-aware offloading,以利用 MoE 推理中的稀疏激活和时间局部性。
- 设计 sequence-level expert activation tracing 以识别并利用专家复用模式。
- 开发 activation-aware 的预取与缓存,以最小化卸载开销。
- 在真实世界的 MoE 模型和服务工作负载上评估系统,以展示延迟和成本收益。
提出的方法
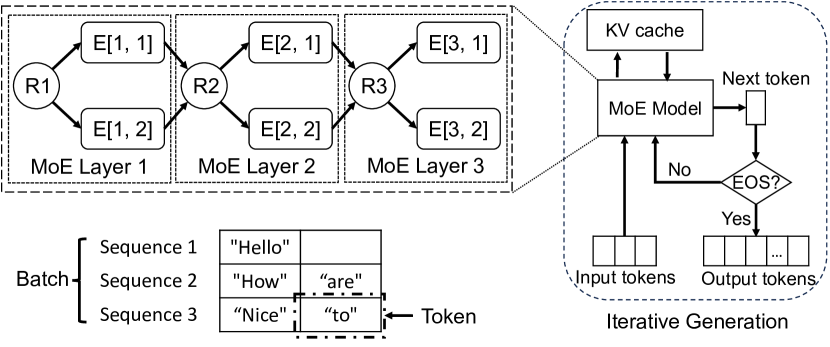
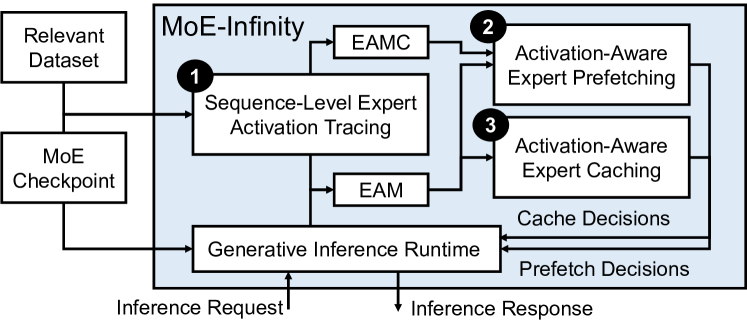
- 引入 sequence-level expert activation tracing,配套 Expert Activation Matrices (EAMs) 以捕捉每序列的激活模式。
- 构建 Expert Activation Matrix Collection (EAMC),通过聚类方法表示多样的激活模式。
- 开发 activation-aware 的专家预取,优先考虑下一次可能被激活且位于当前执行层附近的专家。
- 实现 activation-aware 的专家缓存,采用多层 GPU/主机内存缓存和偏好经常被激活的专家的缓存置换策略。
- 为多-GPU 服务器和专家并行部署整合多层预取与 NUMA 感知优化。
- 在真实的 MoE 检查点(Switch Transformers、NLLB-MoE)上结合 Azure Trace 类工作负载进行评测,以测量延迟和成本改进。
实验结果
研究问题
- RQ1序列级激活跟踪如何改进 MoE 服务的卸载决策?
- RQ2与基线相比,activation-aware 预取和缓存是否能显著降低延迟和部署成本?
- RQ3Expert Activation Matrix Collection 如何适应在线服务中的分布变化?
- RQ4在多-GPU和多服务器部署中,哪些硬件与实现优化能最大化性能?
主要发现
- MoE-Infinity 在与最先进基线相比时实现了4–20X的延迟降低和超过8X的部署成本降低。
- activation-aware 的预取与缓存显著优于传统的 MoE 卸载中的预取/缓存。
- 序列级追踪与 EAMs 捕捉的稀疏激活和时间局部性使得按序列模式能够实现有效的资源放置。
- 该方法可扩展到多-GPU集群并支持专家并行服务,同时对不可用专家提供 SSD 卸载。
- 微基准显示在 DeepSpeed 和 BrainStorm 预取方面以及对 SOTA MoE 系统所用缓存策略上有改进。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。