[论文解读] MotionGPT: Human Motion as a Foreign Language
MotionGPT 将人类运动与语言统一为一个生成模型,通过将运动量化为令牌并使用语言模型骨干来执行多样化的运动任务,利用提示完成文本到运动、运动到文本、预测等任务,取得了在文本到运动、运动到文本、预测及中间任务上的强劲结果。
Though the advancement of pre-trained large language models unfolds, the exploration of building a unified model for language and other multi-modal data, such as motion, remains challenging and untouched so far. Fortunately, human motion displays a semantic coupling akin to human language, often perceived as a form of body language. By fusing language data with large-scale motion models, motion-language pre-training that can enhance the performance of motion-related tasks becomes feasible. Driven by this insight, we propose MotionGPT, a unified, versatile, and user-friendly motion-language model to handle multiple motion-relevant tasks. Specifically, we employ the discrete vector quantization for human motion and transfer 3D motion into motion tokens, similar to the generation process of word tokens. Building upon this "motion vocabulary", we perform language modeling on both motion and text in a unified manner, treating human motion as a specific language. Moreover, inspired by prompt learning, we pre-train MotionGPT with a mixture of motion-language data and fine-tune it on prompt-based question-and-answer tasks. Extensive experiments demonstrate that MotionGPT achieves state-of-the-art performances on multiple motion tasks including text-driven motion generation, motion captioning, motion prediction, and motion in-between.
研究动机与目标
- 激励并实现一个统一的运动-语言预训练框架,以利用大规模语言数据来驱动运动任务。
- 开发一个运动分词器,将连续运动转换为离散令牌,形成一个运动词汇表。
- 训练一个运动感知的语言模型,在同一词汇表中同时处理运动令牌和文本令牌。
- 应用指令微调,使得基于提示的多任务学习能够覆盖多种与运动相关的任务。
提出的方法
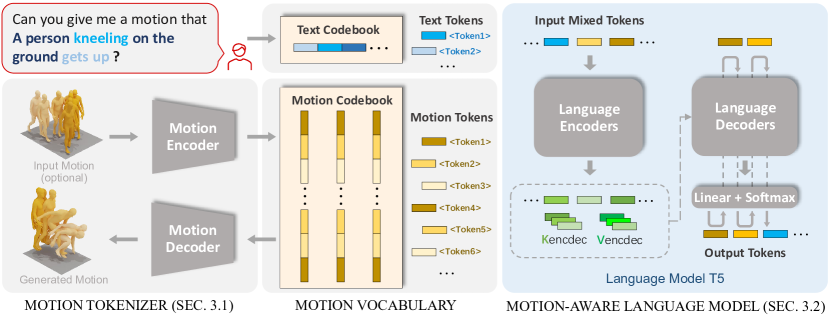
- 引入一个使用 VQ-VAE 的运动分词器,将 M 帧运动转换为来自可学习码本 Z 的 L 个离散运动令牌序列。
- 通过将运动令牌与文本令牌组成为一个统一词汇表 V,使模型能够在单一基于 Transformer 的骨干中处理和生成两种模态。
- 在混合的运动和语言数据上对基于 T5 的运动-语言模型进行预训练,以捕获跨模态语义。
- 应用一个三阶段训练方案:(i) 训练运动分词器,(ii) 使用无监督和有监督目标进行运动-语言预训练,(iii) 使用多样化提示对多种运动任务进行指令微调。
- 利用自回归目标在跨越运动和文本的条件源序列下最大化目标令牌序列的似然性,实现从提示中灵活生成。
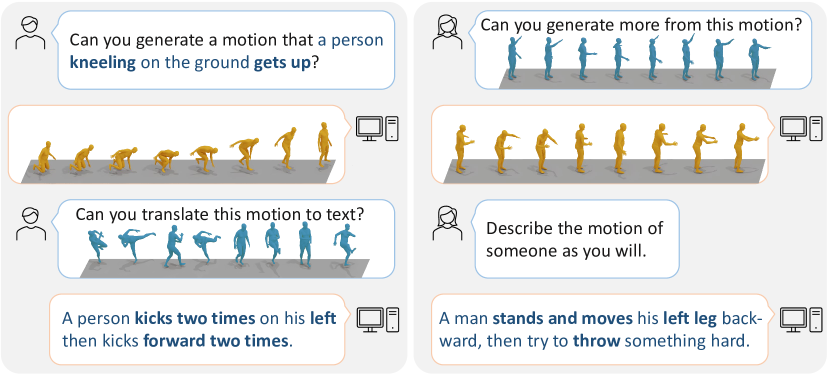
实验结果
研究问题
- RQ1单一统一模型是否能够通过运动-语言框架处理多种运动任务(文本到运动、运动到文本、预测、以及中间任务)?
- RQ2学习离散运动词汇并与语言数据共同训练是否会提升对未见运动-语言任务的泛化能力?
- RQ3使用基于提示的数据集进行指令微调在实现对各种运动任务的零-shot 或少量-shot 自适应方面有多有效?
主要发现
- MotionGPT 在包括文本到运动、运动字幕、运动预测以及运动中间任务在内的多样化运动任务上实现了具有竞争力的或最先进的性能。
- 基于 VQ-VAE 的运动分词器能够将运动有效表示为适合与语言模型集成的离散令牌。
- 在统一词汇表内对运动和语言进行联合训练,使模型能够在单一 Transformer 骨干上对两种模态进行推理。
- 通过大量提示进行指令微调提升了对未知任务的通用性和性能,而在没有足够运动数据的情况下,增大模型规模不一定带来收益。
- 三阶段训练方案(分词器训练、运动-语言预训练、指令微调)对学习跨模态关系被证明是有效的。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。