[论文解读] mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl 引入一种模块化训练范式,使用一个冻结的语言模型、一个可训练的视觉知识模块和一个视觉摘要器,从而实现多模态理解和多轮对话,在 OwlEval 上进行评估。
Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
研究动机与目标
- 在不对大型语言模型进行全面再训练的情况下,推动在LLMs中实现多模态能力。
- 提出一种将视觉基础模型、视觉知识模块和视觉摘要器结合在一起的模块化架构。
- 开发一种两阶段训练范式,在对齐图像与文本的同时保持LLM的生成能力。
- 通过联合指令微调,展示在单模态与多模态指令理解以及多轮对话方面的提升。
提出的方法
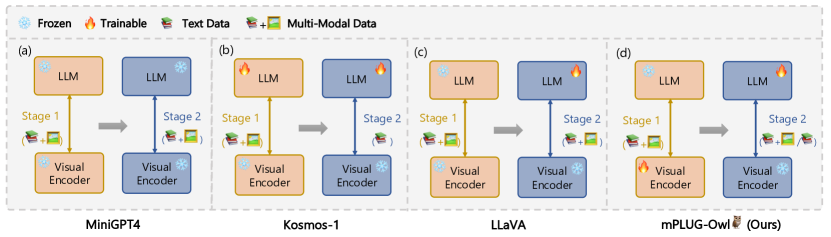
- 使用视觉基础模型 f_V 提取视觉特征。
- 引入一个视觉摘要器 f_K,将视觉特征总结为可学习的令牌。
- 在训练视觉组件以对齐图像-文本表示时冻结语言基础模型 f_L。
- 阶段1:在冻结LLM的情况下,使用图像-说明对训练视觉知识和摘要器。
- 阶段2:在冻结 f_V、对 f_L 和 f_K 训练 LoRA 的情况下,使用语言数据和多模态数据进行联合指令微调。
实验结果
研究问题
- RQ1模块化的视觉-语言结构是否能够将视觉知识与冻结的 LLM 对齐,以实现多模态理解?
- RQ2用多模态数据和文本数据进行两阶段训练,是否相对于基线在单模态和多模态的指令跟随方面都得到提升?
- RQ3来自模块化多模态训练会出现哪些新兴能力(例如多图像相关性、场景文本理解、多语言对话)?
主要发现
- mPLUG-Owl 在 OwlEval 的指令理解和视觉任务上超过了 MiniGPT-4 和 LLaVA 等基线。
- 包含多模态预训练和联合指令微调的两阶段训练方案实现了最佳性能。
- 联合的多模态和文本数据指令提升了知识迁移和推理能力。
- 消融研究表明在指令微调阶段使用多模态数据可以改善视觉知识对齐和文本任务的表现。
- 定性分析揭示了诸如多图像相关性和多语言对话等新兴能力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。