[论文解读] mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration
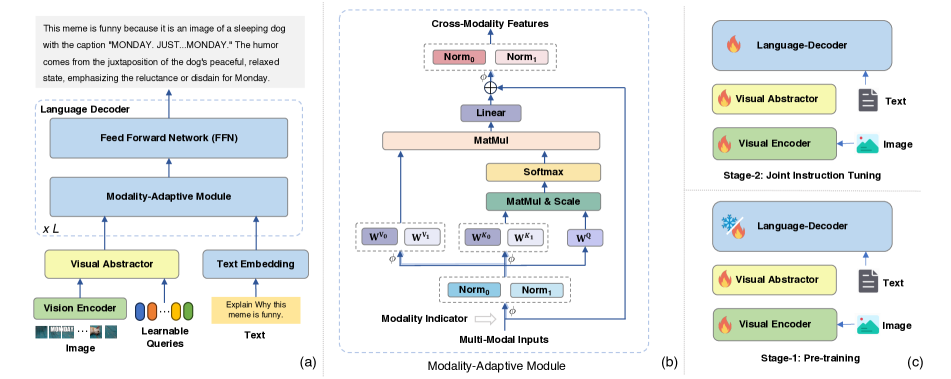
mPLUG-Owl2 引入一个模态自适应语言解码器和一个视觉摘要器,以在保持模态特征的同时实现模态协作,在单一通用模型上实现文本和多模态任务的最新(state-of-the-art)结果。
Multi-modal Large Language Models (MLLMs) have demonstrated impressive instruction abilities across various open-ended tasks. However, previous methods primarily focus on enhancing multi-modal capabilities. In this work, we introduce a versatile multi-modal large language model, mPLUG-Owl2, which effectively leverages modality collaboration to improve performance in both text and multi-modal tasks. mPLUG-Owl2 utilizes a modularized network design, with the language decoder acting as a universal interface for managing different modalities. Specifically, mPLUG-Owl2 incorporates shared functional modules to facilitate modality collaboration and introduces a modality-adaptive module that preserves modality-specific features. Extensive experiments reveal that mPLUG-Owl2 is capable of generalizing both text tasks and multi-modal tasks and achieving state-of-the-art performances with a single generic model. Notably, mPLUG-Owl2 is the first MLLM model that demonstrates the modality collaboration phenomenon in both pure-text and multi-modal scenarios, setting a pioneering path in the development of future multi-modal foundation models.
研究动机与目标
- 通过模态协作提升文本与多模态任务表现,推动通用型多模态基础模型的构建。
- 开发一种模块化架构,实现模态分离但通过共享接口实现跨模态交互。
- 提出一种模态自适应模块,在实现协作的同时保留模态特征。
- 引入两阶段训练范式,结合视觉语言预训练与联合视觉语言指令微调。
- 展示在标准视觉-语言基准和纯文本任务上的强泛化能力。
提出的方法
- 使用具备视觉编码器、视觉摘要器、文本嵌入层,以及语言解码器作为通用接口的模块化架构。
- 引入具有可学习查询的视觉摘要器,用于压缩视觉标记并降低计算量。
- 提出一个模态自适应模块(MAM),将键和值的模态特定投影分离,同时共享查询,实现跨模态协作而不产生粒度干扰。
- 将视觉与语言特征投射到共享的语义空间,同时通过分离的值投影和不同的层归一化来保持模态特征。
- 采用两阶段训练范式:(i) 视觉-语言预训练,使用一个可训练的视觉编码器;(ii) 联合视觉-语言指令微调。
- 在视觉摘要器中使用一组固定、可学习的查询,以提取高层语义特征并在解码前减少序列长度。
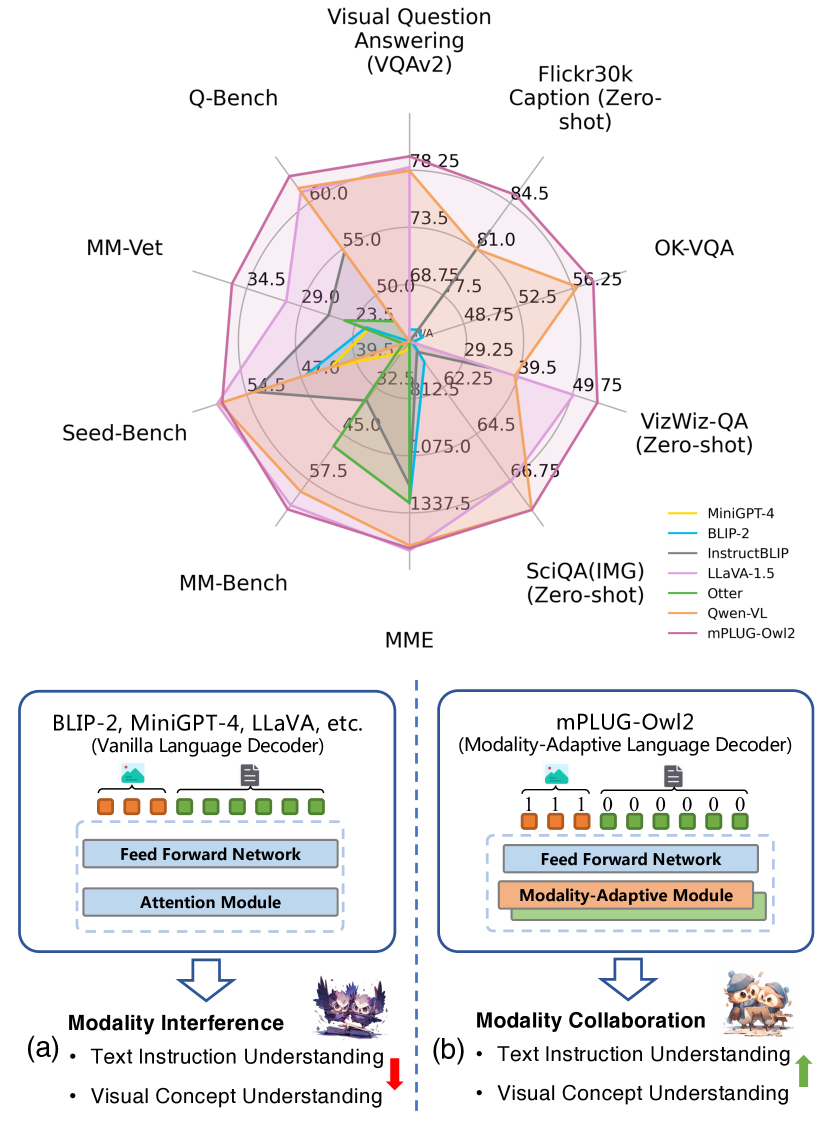
实验结果
研究问题
- RQ1在一个单一通用模型中,模态协作是否能同时提升文本任务和多模态任务的表现?
- RQ2如何设计解码器和注意力机制,以在保持模态特定信息的同时减轻模态干扰?
- RQ3哪种训练方案最能支持视觉语言能力与纯文本能力的联合优化?
- RQ4提高视觉分辨率和视觉摘要器中可学习查询的数量是否能提升在OCR密集和细粒度任务上的表现?
- RQ5所提模态自适应模块在各基准上的零-shot与指令微调性能有何影响?
主要发现
- mPLUG-Owl2 在一个单一通用模型上在八个视觉-语言基准上达到最先进的性能。
- 该模型在多模态基准如 MMBench、MM-Vet、Q-Bench 上展示出强大的零-shot表现,在 MME 上则具备竞争力。
- 纯文本基准也有所提升,相较于其他指令微调的 LLM,在 MMLU 和 BBH 上有显著提升。
- 模态自适应模块(MAM)在减少模态干扰的同时实现模态协作,通过注意力可视化和消融研究得到证明。
- 使用可训练视觉编码器的联合视觉-语言指令微调在多模态和文本上都表现出色,当两种模态共同训练时,MAM 进一步稳定了收益。
- 提高图像分辨率和视觉摘要器中可学习查询的数量可显著提升在 OCR 密集和细粒度视觉-语言任务上的表现。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。