[论文解读] Nemotron-4 340B Technical Report
Nemotron-4-340B 模型家族(Base、Instruct、Reward)开源,强烈强调用于对齐的合成数据,在 RewardBench 取得高分,并在标准基准测试中取得有竞争力的结果。
We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
研究动机与目标
- 在宽松许可下发布一个 340B 规模的开源语言模型家族。
- 展示在按指令执行、对话能力和基于奖励的对齐方面的强大性能。
- 展示用于模型对齐与数据效率的合成数据生成的有效性。
- 提供详细的训练数据、流程和代码以促进可重复性和社区使用。
提出的方法
- 对包含英文、多语言和代码数据的 9T 标记进行多流预训练。
- 仅解码器的 Transformer 架构,使用 RoPE、SentencePiece、分组查询注意力,并且不使用偏置项。
- 两阶段对齐:有监督微调(SFT)随后进行偏好微调(DPO 和 RPO)。
- 在对齐中大量使用合成数据(>98%),配合合成数据生成管线和 HelpSteer2 奖励数据。
- 迭代式的弱到强对齐,以持续提升生成器质量和模型能力。
- 发布 Nemotron-4-340B-Reward 作为高质量的奖励模型,用于引导对齐和数据筛选。
实验结果
研究问题
- RQ1Nemotron-4-340B-Base 与开放获取基线在标准推理和基准任务上的表现如何?
- RQ2与仅有人工标注数据相比,合成数据生成在对齐大语言模型方面的效果如何?
- RQ3奖励建模与带有人类反馈的强化学习(RLHF)对遵循指令和安全性有何影响?
- RQ4迭代式的弱到强对齐是否能提升数据质量和模型性能,超越传统单次对齐?
- RQ5两阶段 SFT 的影响,特别是以代码模型为焦点的 SFT 然后再进行通用 SFT,对下游任务有何影响?
主要发现
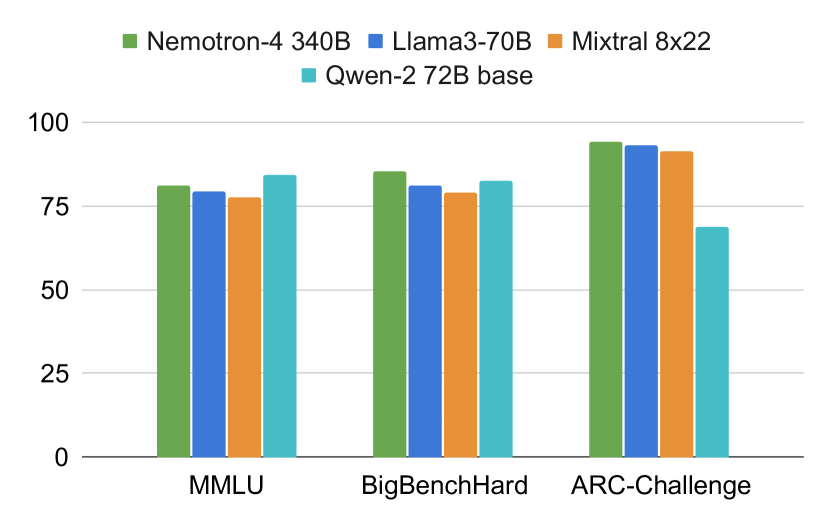
| 尺寸 | ARC-c | Winogrande | Hellaswag | MMLU | BBH | HumanEval | |
|---|---|---|---|---|---|---|---|
| Mistral 8x22B | 91.30 | 84.70 | 88.50 | 77.75 | 78.90 | 45.10 | |
| Llama-3 70B | 93.00 | 85.30 | ∗ | 88.00 | 79.50 | 81.30 | ∗ |
| Qwen-2 72B | 68.90 | 85.10 | 87.60 | 84.20 | 82.40 | 64.60 | |
| Nemotron-4-340B-Base 340B | 94.28 | 89.50 | 90.53 | 81.10 | 85.44 | 57.32 |
- Nemotron-4-340B-Base 在所列开放获取基线中在常识推理任务和 BBH 上取得最高准确率。
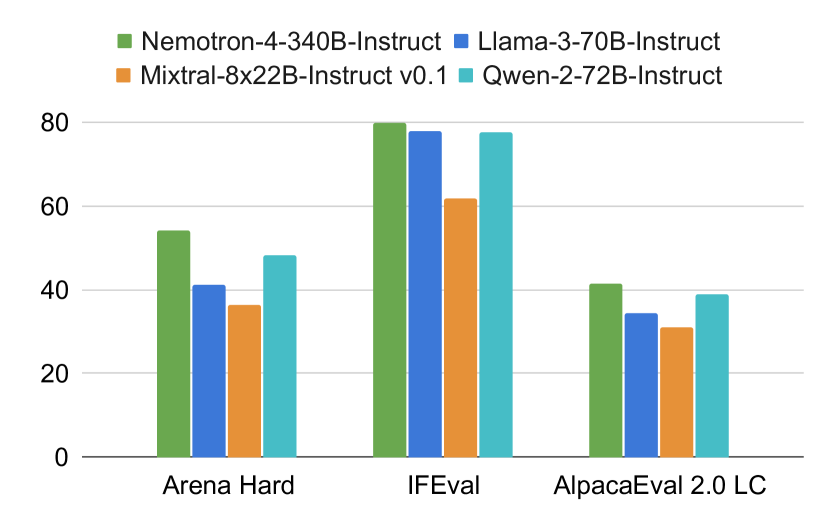
- Nemotron-4-340B-Instruct 在指令执行和对话能力方面超越了相应的 Instruct 模型。
- Nemotron-4-340B-Reward 在 RewardBench 取得最高准确率,在发表时超越了多些专有模型。
- 超过 98% 的对齐数据是合成生成的,证明了用于模型对齐的合成数据生成的有效性。
- 作者发布了合成数据管线、生成提示和奖励模型,以支持开放研究和可重复性。
- Base 模型包含 9.4B 嵌入参数和 331.6B 非嵌入参数,使用 9T 标记在一个 96 层的 Transformer 上训练。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。