[论文解读] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
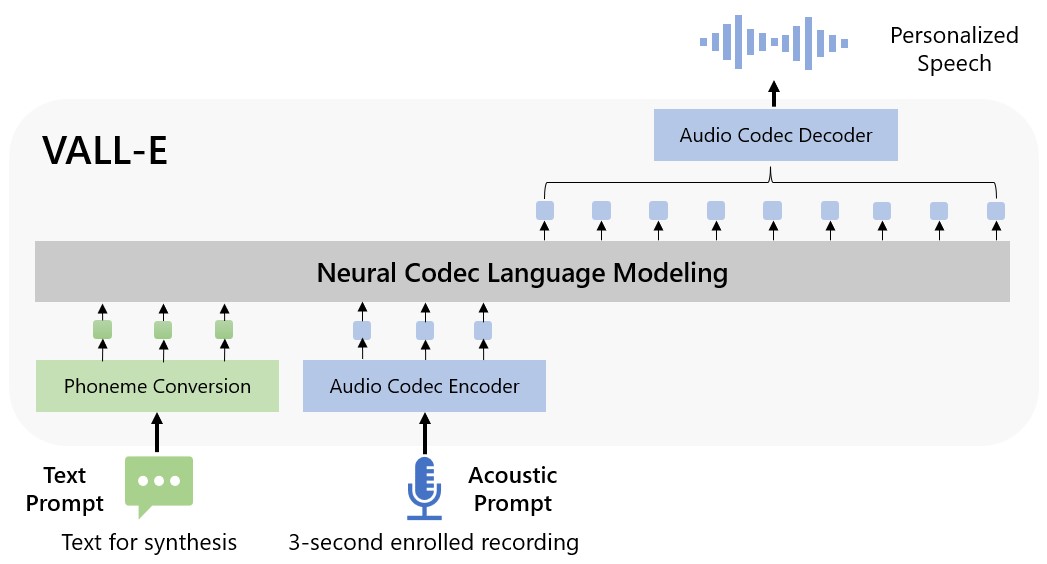
本文提出 VALL-E,一种基于语言模型的 TTS 系统,使用离散音频编解码器编码和从已注册录音中获得的提示,进行零-shot TTS,具有强自然性和说话人相似性,训练数据量为 60k 小时。
We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See https://aka.ms/valle for demos of our work.
研究动机与目标
- 将 TTS 训练数据扩展到数十万小时,以提升零-shot 泛化。
- 将 TTS 视为条件语言模型,使用离散音频编解码码作为中间表示。
- 启用基于提示的、上下文学习,以从 3 秒注册录音合成未知说话人。
- 在合成过程中保持说话人情感和声学环境。
- 在 LibriSpeech 和 VCTK 上对比最先进基线展示出更优的零-shot 性能。
提出的方法
- 使用现成的神经音频编解码器(EnCodec)提取的离散码来表征语音。
- 将 TTS 作为条件编解码器语言模型,给定来自注册记录的音素提示和声学提示,生成声学码矩阵。
- 使用分层模型,第一量化器采用自回归解码器,其余量化器使用非自回归模型,以在质量和速度之间取得平衡。
- 在 60k 小时的 LibriLight 数据上训练,约 7k 说话人,使用 ASR 生成的转录作为监督。
- 采用基于提示的推理,结合音素提示和声学提示,实现对未知说话人的零-shot 合成。
- 用 WER 和说话人相似度度量,以及人类 CMOS/SMOS 评分进行评估。
实验结果
研究问题
- RQ1通过将合成视为对离散声学码的条件语言建模,是否可以实现零-shot TTS?
- RQ2扩大半监督语音数据是否提升零-shot TTS 的性能和对未知说话人的泛化?
- RQ3是否可以通过基于提示的上下文学习,在不进行微调的情况下实现自然且对说话人忠实的语音?
- RQ4自回归(AR)与非自回归(NAR)组件如何影响合成质量和推理速度?
- RQ5VALL-E 在标准 TTS 和跨数据集评估(LibriSpeech、VCTK)上的鲁棒性如何?
主要发现
| 模型 | WER | SPK |
|---|---|---|
| GroundTruth | 2.2 | 0.754 |
| GSLM | 12.4 | 0.126 |
| AudioLM* | 6.0 | - |
| YourTTS | 7.7 | 0.337 |
| VALL-E | 5.9 | 0.580 |
| VALL-E-continual | 3.8 | 0.508 |
- VALL-E 在 LibriSpeech 和 VCTK 上显著超越基线的最先进零-shot TTS,在语音自然性和说话人相似性方面。
- 在 LibriSpeech 上,VALL-E 相对于基线在 CMOS 上提升 +0.12,在 SMOS 上提升 +0.93;在 VCTK 上,相对于真实语音的 CMOS 为 +0.23,SMOS 为 +0.04。
- VALL-E-continual(使用真实 3s 提示进行续写)将 WER 降至 3.8,并保持强的说话人相似性(SMOS 0.508)。
- 人工评估显示 VALL-E 在 SMOS 上接近真实语音(0. 差异在边际内),并且相对于基线的 CMOS 提升(在 LibriSpeech 上 +0.12;在 VCTK 上 +0.23)。
- 消融研究表明音素提示(降低 WER)和声学提示(提升说话人相似度)起着关键作用。
- 与其他语音到语音语言模型系统(GSLM、AudioLM)相比,VALL-E 展示出在零-shot TTS 中更高的鲁棒性和说话人保真度。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。