[论文解读] NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models
NV-Embed 使用一个解码器-仅 LLM 作为多功能嵌入模型,采用潜在注意力池化层、对比学习中的双向注意力,以及使用公开数据的两阶段指令微调过程,在 MTEB 与 BEIR 基准测试中取得领先分数。
Decoder-only LLM-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce NV-Embed, incorporating architectural designs, training procedures, and curated datasets to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For training algorithm, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. For training data, we utilize the hard-negative mining, synthetic data generation and existing public available datasets to boost the performance of embedding model. By combining these techniques, our NV-Embed-v1 and NV-Embed-v2 models obtained the No.1 position on the MTEB leaderboard (as of May 24 and August 30, 2024, respectively) across 56 tasks, demonstrating the sustained effectiveness of the proposed methods over time. It also achieved the highest scores in the Long Doc section and the second-highest scores in the QA section of the AIR Benchmark, which covers a range of out-of-domain information retrieval topics beyond those in MTEB. We further provide the analysis of model compression techniques for generalist embedding models.
研究动机与目标
- 用解码器-仅 LLM 在检索与非检索任务中推进通用文本嵌入。
- 引入架构创新以改进池化与表示学习。
- 仅使用公开数据集开发两阶段指令微调的训练方案。
- 在 MTEB 与 BEIR 基准上展示最先进的性能。
- 保持嵌入模型的简洁性与可重复性。
提出的方法
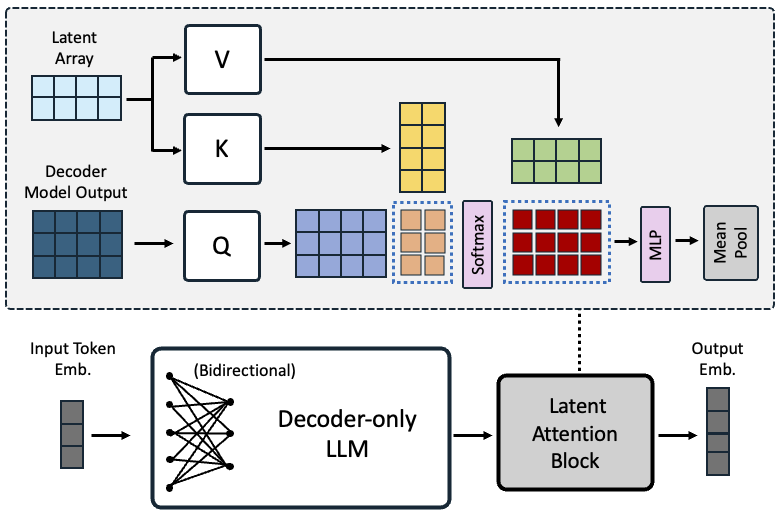
- 提出一个潜在注意力层来对序列嵌入进行池化,替代均值池化或 EOS token 池化。
- 在对比训练中移除因果注意力掩码,以实现双向表示学习。
- 采用两阶段对比指令微调:第一阶段使用带组内负样本和困难负样本的检索数据集;第二阶段将非检索数据混合在一起,不使用组内负样本。
- 仅使用公开数据,避免用于训练的专有合成数据。
- 基础模型为 Mistral-7B;端到端训练,使用 LoRA,最大序列长度 512、批量大小 128(1 个正样本 + 7 个困难负样本)。
- 在完整的 MTEB 基准测试(56 个任务)和 BEIR 子集(15 个检索任务)上评估,并与前沿嵌入模型进行对比。
实验结果
研究问题
- RQ1在使用合适的池化机制和训练策略时,解码器-仅 LLM 是否能在通用嵌入任务中超过双向嵌入模型?
- RQ2移除因果注意力掩码并使用潜在注意力池化层是否能提升检索与非检索任务的嵌入质量?
- RQ3先以检索为重点并使用组内负样本的两阶段指令微调制度,再将非检索数据混合而不使用组内负样本,会带来哪些提升?
- RQ4仅使用公开数据进行训练是否能够在 MTEB/BEIR 上达到最先进的分数,而无需专有合成数据?
主要发现
- NV-Embed 实现了在 56 个任务上创纪录的 MTEB 得分 69.32。
- 在 15 个检索任务上达到最高的 BEIR 检索分数 59.36。
- 在对比训练中双向注意力持续优于因果注意力。
- 潜在注意力池化在检索、分类和 STS 任务上比均值池化和基于 EOS 的池化表现更好。
- 两阶段指令微调(检索优先且使用组内负样本,其次混合检索/非检索)提升了检索和非检索任务的性能。
- 所有结果均来自公开数据,NV-Embed 从头开始在 Mistral 7B 上训练。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。