[论文解读] On the Connection Between MPNN and Graph Transformer
本文表明,带有虚拟节点的 MPNN 能在各种深度-宽度权衡下任意近似图变换器中的自注意力,并在多个基准上提供经验证据。
Graph Transformer (GT) recently has emerged as a new paradigm of graph learning algorithms, outperforming the previously popular Message Passing Neural Network (MPNN) on multiple benchmarks. Previous work (Kim et al., 2022) shows that with proper position embedding, GT can approximate MPNN arbitrarily well, implying that GT is at least as powerful as MPNN. In this paper, we study the inverse connection and show that MPNN with virtual node (VN), a commonly used heuristic with little theoretical understanding, is powerful enough to arbitrarily approximate the self-attention layer of GT. In particular, we first show that if we consider one type of linear transformer, the so-called Performer/Linear Transformer (Choromanski et al., 2020; Katharopoulos et al., 2020), then MPNN + VN with only O(1) depth and O(1) width can approximate a self-attention layer in Performer/Linear Transformer. Next, via a connection between MPNN + VN and DeepSets, we prove the MPNN + VN with O(n^d) width and O(1) depth can approximate the self-attention layer arbitrarily well, where d is the input feature dimension. Lastly, under some assumptions, we provide an explicit construction of MPNN + VN with O(1) width and O(n) depth approximating the self-attention layer in GT arbitrarily well. On the empirical side, we demonstrate that 1) MPNN + VN is a surprisingly strong baseline, outperforming GT on the recently proposed Long Range Graph Benchmark (LRGB) dataset, 2) our MPNN + VN improves over early implementation on a wide range of OGB datasets and 3) MPNN + VN outperforms Linear Transformer and MPNN on the climate modeling task.
研究动机与目标
- 研究带有虚拟节点的 MPNN 是否能够近似 Graph Transformer 的自注意力。
- 在不同 Transformer 变体下,表征 MPNN + VN 近似自注意力的深度-宽度权衡。
- 建立 MPNN+VN、DeepSets 与置换等变性普适性之间的联系。
- 在 Long Range Graph Benchmark (LRGB) 及其他数据集上提供实证证据,将 MPNN+VN 与 GT 及其他基线进行比较。
提出的方法
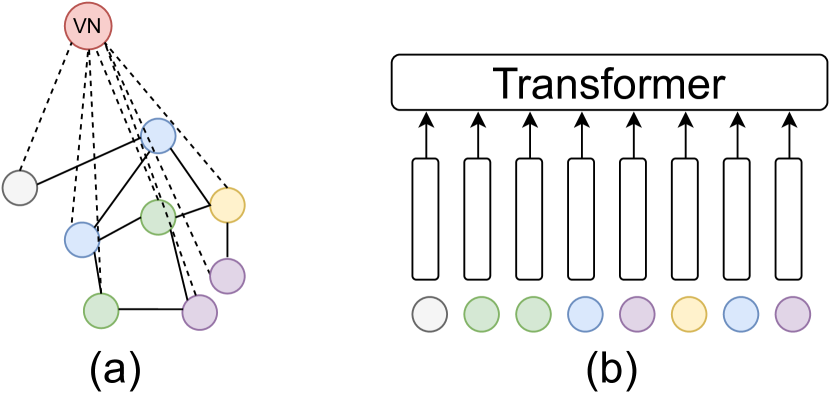
- 定义异质和简化的异质 MPNN + VN 层以建模全局交互。
- 证明 O(1) 深度和 O(1) 宽度的 MPNN + VN 能近似 Performer/Linear Transformer 的自注意力。
- 利用与 DeepSets 的联系,展示 O(1) 深度和 O(n^d) 宽度的普适近似。
- 在强特征假设下,构造 O(1) 宽度和 O(n) 深度的 MPNN + VN,使其近似自注意力。
- 给出实证结果,表明 MPNN + VN 在 LRGB 和 OGB 数据集上具有竞争力或更优,在气候建模任务中也表现良好。
实验结果
研究问题
- RQ1MPNN + VN 能否近似 Graph Transformers 中使用的自注意力层?
- RQ2在不同 transformer 公式下,哪些深度-宽度组合足以使 MPNN + VN 复现 GT 的注意力?
- RQ3MPNN + VN 方法与 DeepSets 及置换等变性普适性之间有何联系?
- RQ4实证结果是否支持 MPNN + VN 作为标准图基准上的强基线?
主要发现
| Depth | Width | Self-Attention | Notes |
|---|---|---|---|
| O(1) | O(1) | Approximate | Approximate self attention in Performer (Choromanski et al., 2020 ) |
| O(1) | O(n^d) | Full | Leverage the universality of equivariant DeepSets |
| O(n) | O(1) | Full | Explicit construction, strong assumption on 𝑋 |
| O(n) | O(1) | Full | Explicit construction, more relaxed (but still strong) assumption on 𝑋 |
- O(1) 深度和 O(1) 宽度的 MPNN + VN 可以近似 Performer/Linear Transformer 的自注意力。
- O(1) 深度和 O(n^d) 宽度的 MPNN + VN 具有置换等变性普适性,因此可以通过 DeepSets 近似自注意力和完整的变换器。
- 在某些特征假设下,存在 O(n) 深度和 O(1) 宽度的结构,可以任意好地近似自注意力;假设较强。
- 实证地,MPNN + VN 在 LRBG 上优于某些 Graph Transformer,在 OGB 数据集上改进了早期的 MPNN+VN 实现;在气候建模任务上也优于 Linear Transformer 和普通的 MPNN。
- 理论联系表明,MPNN + VN 可以在两层中精确模拟 DeepSets,为普适近似结果提供理论支撑。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。