QUICK REVIEW
[论文解读] OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao|arXiv (Cornell University)|Aug 2, 2023
Multimodal Machine Learning Applications被引用 70
一句话总结
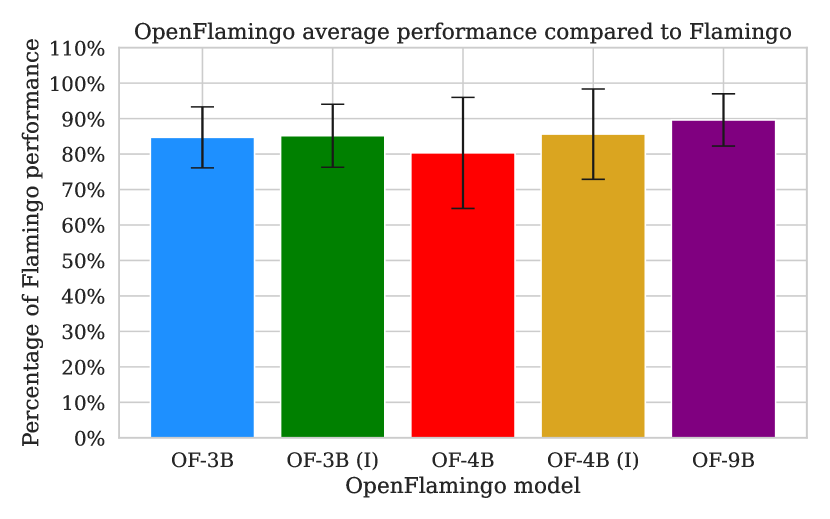
OpenFlamingo 提供开源自回归视觉-语言模型(3B–9B),在网页数据上训练,在七个数据集上通过上下文演示实现大约是 Flamingo 性能的 80–89%。
ABSTRACT
We introduce OpenFlamingo, a family of autoregressive vision-language models ranging from 3B to 9B parameters. OpenFlamingo is an ongoing effort to produce an open-source replication of DeepMind's Flamingo models. On seven vision-language datasets, OpenFlamingo models average between 80 - 89% of corresponding Flamingo performance. This technical report describes our models, training data, hyperparameters, and evaluation suite. We share our models and code at https://github.com/mlfoundations/open_flamingo.
研究动机与目标
- 推动创建一个开源的自回归视觉-语言框架,以便在没有专有权重或数据的情况下进行研究。
- 使用公开的编码器和解码器重现 Flamingo 风格的跨注意力视觉-语言架构。
- 在多样化的视觉-语言任务上评估开源模型,使用上下文演示以评估泛化和少样本能力。
- 分析数据源和训练选择,以了解相对于闭源系列模型的性能差距。
提出的方法
- 通过使用可训练的跨注意力模块,将冻结的语言模型与冻结的视觉编码器进行跨注意,来复现 Flamingo 架构。
- 通过冻结的视觉编码器(CLIP ViT-L/14)对图像进行嵌入,并训练一个 Perceiver 重采样器来生成图像嵌入。
- 在开源网页抓取的数据集 LAION-2B(图文对)和 Multimodal C4(MMC4)上训练,并对某些模型使用 ChatGPT 生成的序列。
- 用 <image> 和 <|endofchunk|> 标记对序列进行预处理,并使用 AdamW 优化进行下一个标记预测。
- 在 3B、4B、和 9B 参数规模上进行实验,包括标准和指令调优(instruction-tuned)的语言主干。
- 使用七个视觉-语言基准测试进行评估,具有不同数量的上下文示例(0、4、8、16、32),在某些设置中还使用基于检索的上下文示例选择(RICES)。
实验结果
研究问题
- RQ1开放源代码的自回归视觉-语言模型在多样化任务上能达到 Flamingo 的多大程度?
- RQ2模型大小(3B、4B、9B)和语言模型主干(标准与指令调优)对零-shot 和上下文学习表现有何影响?
- RQ3开放训练数据(LAION-2B 与 MMC4)以及数据处理选择如何影响上下文学习和 VQA 风格任务?
- RQ4可训练与冻结的图像及片段末尾嵌入在下游性能中起到何种作用?
- RQ5与微调的最先进方法相比,开源模型在使用上下文演示时是否能取得有竞争力的结果?
主要发现
| Benchmark | Shots | Fl-3B | Fl-9B | OF-3B | OF-3B (I) | OF-4B | OF-4B (I) | OF-9B |
|---|---|---|---|---|---|---|---|---|
| COCO | 0 | 73.0 | 79.4 | 74.9 (0.2) | 74.4 (0.6) | 76.7 (0.2) | 81.2 (0.3) | 79.5 (0.2) |
| COCO | 4 | 85.0 | 93.1 | 77.3 (0.3) | 82.7 (0.7) | 81.8 (0.4) | 85.8 (0.5) | 89.0 (0.3) |
| COCO | 32 | 99.0 | 106.3 | 93.0 (0.6) | 94.8 (0.3) | 95.1 (0.3) | 99.2 (0.3) | 99.5 (0.1) |
| Flickr-30K | 0 | 60.6 | 61.5 | 52.3 (1.0) | 51.2 (0.2) | 53.6 (0.9) | 55.6 (1.3) | 59.5 (1.0) |
| Flickr-30K | 4 | 72.0 | 72.6 | 57.2 (0.4) | 59.1 (0.3) | 60.7 (1.2) | 61.2 (0.5) | 65.8 (0.6) |
| Flickr-30K | 32 | 71.2 | 72.8 | 61.1 (1.3) | 64.5 (1.3) | 56.9 (0.7) | 53.0 (0.5) | 61.3 (0.7) |
| VQAv2 | 0 | 49.2 | 51.8 | 44.6 (0.0) | 44.1 (0.1) | 45.1 (0.1) | 46.9 (0.0) | 52.7 (0.2) |
| VQAv2 | 4 | 53.2 | 56.3 | 45.8 (0.0) | 45.7 (0.1) | 49.0 (0.0) | 49.0 (0.0) | 54.8 (0.0) |
| VQAv2 | 32 | 57.1 | 60.4 | 47.0 (0.1) | 44.8 (0.1) | 43.0 (0.2) | 47.3 (0.0) | 53.3 (0.1) |
| OK-VQA | 0 | 41.2 | 44.7 | 28.2 (0.2) | 28.7 (0.1) | 30.7 (0.1) | 31.7 (0.1) | 37.8 (0.2) |
| OK-VQA | 4 | 43.3 | 49.3 | 30.3 (0.5) | 30.6 (0.2) | 35.1 (0.0) | 34.6 (0.0) | 40.1 (0.1) |
| OK-VQA | 32 | 45.9 | 51.0 | 31.0 (0.1) | 30.6 (0.1) | 26.4 (0.2) | 34.7 (0.3) | 42.4 (0.0) |
| TextVQA | 0 | 30.1 | 31.8 | 24.2 (0.2) | 23.1 (0.2) | 21.0 (0.3) | 21.1 (0.4) | 24.2 (0.5) |
| TextVQA | 4 | 32.7 | 33.6 | 27.0 (0.3) | 28.1 (0.4) | 25.9 (0.0) | 27.2 (0.3) | 28.2 (0.4) |
| TextVQA | 32 | 30.6 | 32.6 | 28.3 (0.2) | 28.5 (0.1) | 14.1 (0.2) | 23.2 (0.2) | 23.8 (0.2) |
| VizWiz | 0 | 28.9 | 28.8 | 23.7 (0.5) | 23.4 (0.3) | 18.8 (0.1) | 21.5 (0.2) | 27.5 (0.2) |
| VizWiz | 4 | 34.0 | 34.9 | 27.0 (0.3) | 27.7 (0.1) | 26.6 (0.5) | 26.5 (0.4) | 34.1 (0.7) |
| VizWiz | 32 | 45.5 | 44.0 | 39.8 (0.1) | 39.3 (0.4) | 23.1 (1.1) | 31.3 (0.2) | 44.0 (0.5) |
| HatefulMemes | 0 | 53.7 | 57.0 | 51.2 (2.5) | 50.1 (2.2) | 52.3 (2.3) | 53.1 (2.2) | 51.6 (1.8) |
| HatefulMemes | 4 | 53.6 | 62.7 | 50.6 (0.8) | 49.5 (0.6) | 51.5 (1.4) | 54.9 (1.1) | 54.0 (2.0) |
| HatefulMemes | 32 | 56.3 | 63.5 | 50.2 (1.8) | 47.8 (2.2) | 52.2 (1.2) | 54.9 (1.1) | 53.8 (2.1) |
- OpenFlamingo-3B 和 -9B 在七个数据集上的平均性能分别达到 Flamingo 的 85% 和 89%。
- 在 0-shot 和 4-shot 设置中,OpenFlamingo-9B 在若干数据集接近 Flamingo-9B,并在 COCO、VQAv2、VizWiz 上几乎匹配其 4-shot 性能。
- OpenFlamingo-4B 模型常常不如 3B 模型,冻结与图像相关的嵌入会显著降低性能(例如 COCO 和 VQAv2)。
- 语言指令调优(language-instruction-tuning)提升了部分 OpenFlamingo 变体,RedPajama-3B 主干尤为显著。
- OpenFlamingo-9B 获得了实质性但非最先进的提升;与微调的 SOTA 论文相比,在 32 次 RICES 演示下,其平均达到微调 SoTA 的约 62%。
- 不同数据集的性能趋势不同;VQAv2 对语言模型选择极为敏感,而基于 COCO 的 CIDEr 分数在更多上下文示例下持续改进。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。