[论文解读] pixelNeRF: Neural Radiance Fields from One or Few Images
pixelNeRF 学习一个前馈式、图像条件的 NeRF,能够通过将 NeRF 条件化为像素对齐的图像特征并聚合多视图,在只有一张或几张输入图像时合成新视图,而无需在测试时进行优化。
We propose pixelNeRF, a learning framework that predicts a continuous neural scene representation conditioned on one or few input images. The existing approach for constructing neural radiance fields involves optimizing the representation to every scene independently, requiring many calibrated views and significant compute time. We take a step towards resolving these shortcomings by introducing an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one). Leveraging the volume rendering approach of NeRF, our model can be trained directly from images with no explicit 3D supervision. We conduct extensive experiments on ShapeNet benchmarks for single image novel view synthesis tasks with held-out objects as well as entire unseen categories. We further demonstrate the flexibility of pixelNeRF by demonstrating it on multi-object ShapeNet scenes and real scenes from the DTU dataset. In all cases, pixelNeRF outperforms current state-of-the-art baselines for novel view synthesis and single image 3D reconstruction. For the video and code, please visit the project website: https://alexyu.net/pixelnerf
研究动机与目标
- 通过在跨场景学习场景先验来激发并实现极少输入视图的 novel view 合成。
- 用一个前馈模型替代每场景优化,使其能够泛化到未见过的对象和类别。
- 通过在视角空间将 NeRF 条件化为像素对齐的图像特征来保持空间对齐。
- 在测试时允许可变数量的输入视图,而无需测试时优化。
提出的方法
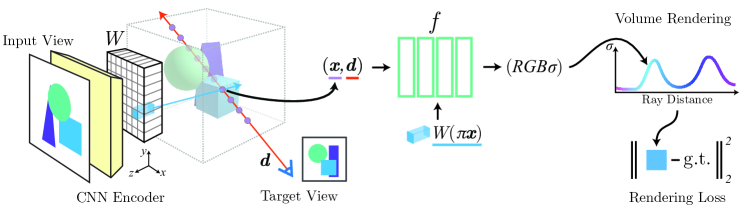
- 从输入图像计算一个全卷积的图像特征网格,并通过投影和双线性插值为查询点采样逐像素特征。
- 通过将其作为残差添加到 NeRF MLP 的每一层来将空间图像特征条件化到 NeRF 网络中。
- 对于多视图输入,将每个视图编码为特征体积,投影到每个视图,使用初始的 NeRF 块分别处理,然后在最终层之前通过平均聚合以预测密度和颜色。
- 在相机/视图空间中操作,而非规范场景空间,以提高对未见类别和多对象场景的泛化。
- 端到端训练,使用体积渲染损失比较渲染图像和真实图像,而不需要显式的 3D 监督。
- 通过在视图之间聚合信息,将从单视图扩展到多视图输入,从而实现少样本重建。
实验结果
研究问题
- RQ1在跨大量场景进行训练时,单张或少量输入图像是否足以预测一个场景的连贯 NeRF 表示?
- RQ2在像素对齐的图像特征上条件化 NeRF,是否能够在没有显式 3D 监督的情况下对未见类别和多对象场景实现泛化?
- RQ3视图空间条件化与多视图聚合对 ShapeNet 和真实世界数据集的新视图合成质量有何影响?
- RQ4该方法在测试时是否可以支持可变数量的输入视图,而无需测试时优化?
主要发现
- PixelNeRF 在少-shot 新视图合成基准上获得类似于最先进水平的表现,相较于 SRN 和 DVR 基线。
- 该方法尽管在合成数据和受限场景上训练,仍对未见对象类别与真实图像(DTU)具有泛化能力。
- 使用本地的、像素对齐的图像特征并结合视图方向,相较于全局潜在码,能提升重建质量和细节。
- 多视图条件化实现了多对象场景的准确360度重建,并展示了汽车图像的 sim-to-real 转换。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。