[论文解读] Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models
本文通过标准化评估套件和模块化训练框架,探究可视条件语言模型(VLM)的设计选择,提出 Prism s,在 7B/13B 规模下优于开放基线。
Visually-conditioned language models (VLMs) have seen growing adoption in applications such as visual dialogue, scene understanding, and robotic task planning; adoption that has fueled a wealth of new models such as LLaVa, InstructBLIP, and PaLI-3. Despite the volume of new releases, key design decisions around image preprocessing, architecture, and optimization are under-explored, making it challenging to understand what factors account for model performance $-$ a challenge further complicated by the lack of objective, consistent evaluations. To address these gaps, we first compile a suite of standardized evaluations spanning visual question answering, object localization, and challenge sets that probe properties such as hallucination; evaluations that provide fine-grained insight VLM capabilities. Second, we rigorously investigate VLMs along key design axes, including pretrained visual representations and training from base vs. instruct-tuned language models, amongst others. We couple our analysis with three resource contributions: (1) a unified framework for evaluating VLMs, (2) optimized, flexible training code, and (3) checkpoints for all models, including a family of VLMs at the 7-13B scale that strictly outperform InstructBLIP and LLaVa v1.5, the state-of-the-art in open VLMs.
研究动机与目标
- 为 VLM 提供覆盖 VQA、定位和挑战任务的标准化、细粒度评估套件。
- 系统性分析 VLM 的关键设计轴,包括优化、图像处理、视觉表示和语言模型。
- 提供一个优化、灵活的 VLM 训练代码库和检查点,以实现可重复性和未来研究。
提出的方法
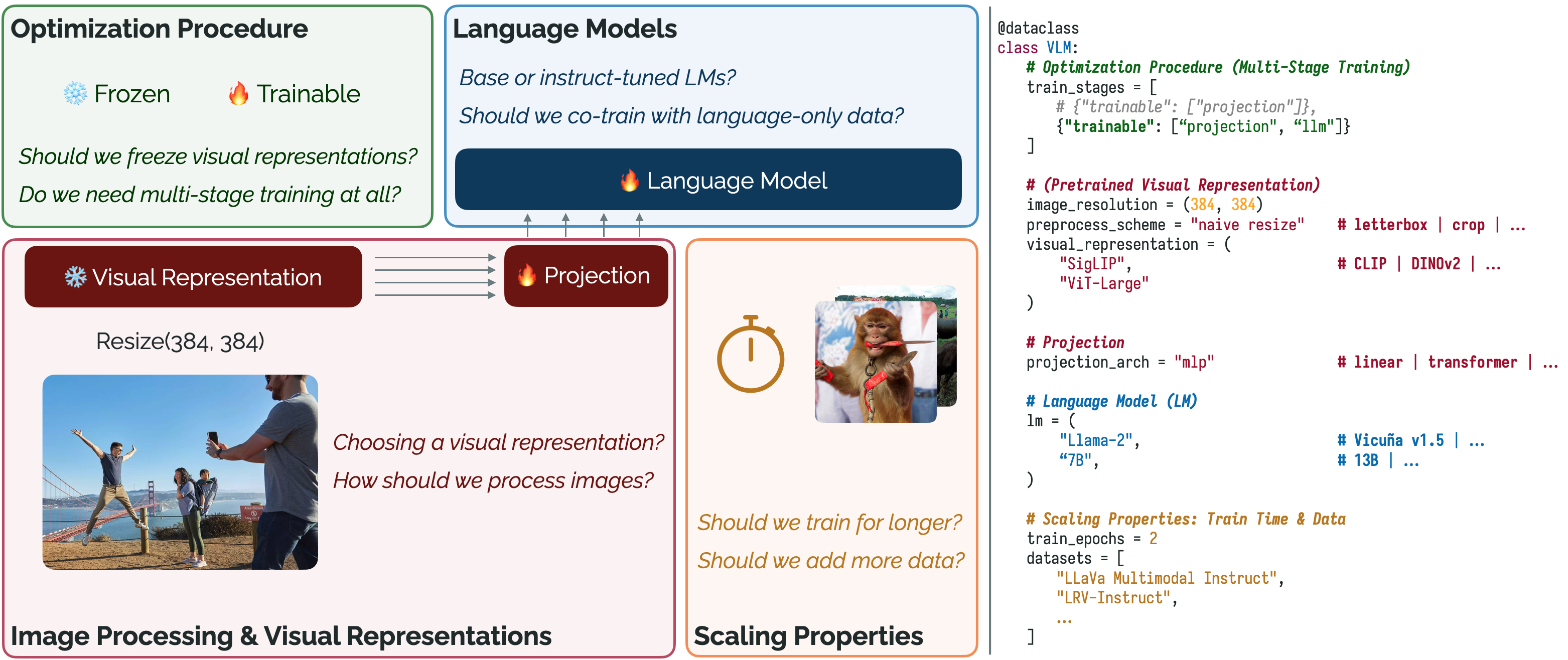
- 采用一个简单的 Patch-as-token VLM 架构,包含预训练的视觉主干、视觉-语言投影和语言模型。
- 使用一个完全开放的预训练数据混合(LLaVa v1.5 组件)和单阶段训练,以对比多阶段流水线。
- 开发并发布一个使用 PyTorch、Fully Sharded Data Parallel (FSDP) 与 BF16 混合精度的优化训练框架。
- 构建一个包含 VQA、定位和挑战集 Eleven 个基准的开放评估套件,以探测能力与幻觉风险。
- 在四个设计轴上进行实验:优化过程、图像处理/视觉表示、语言模型和缩放属性。
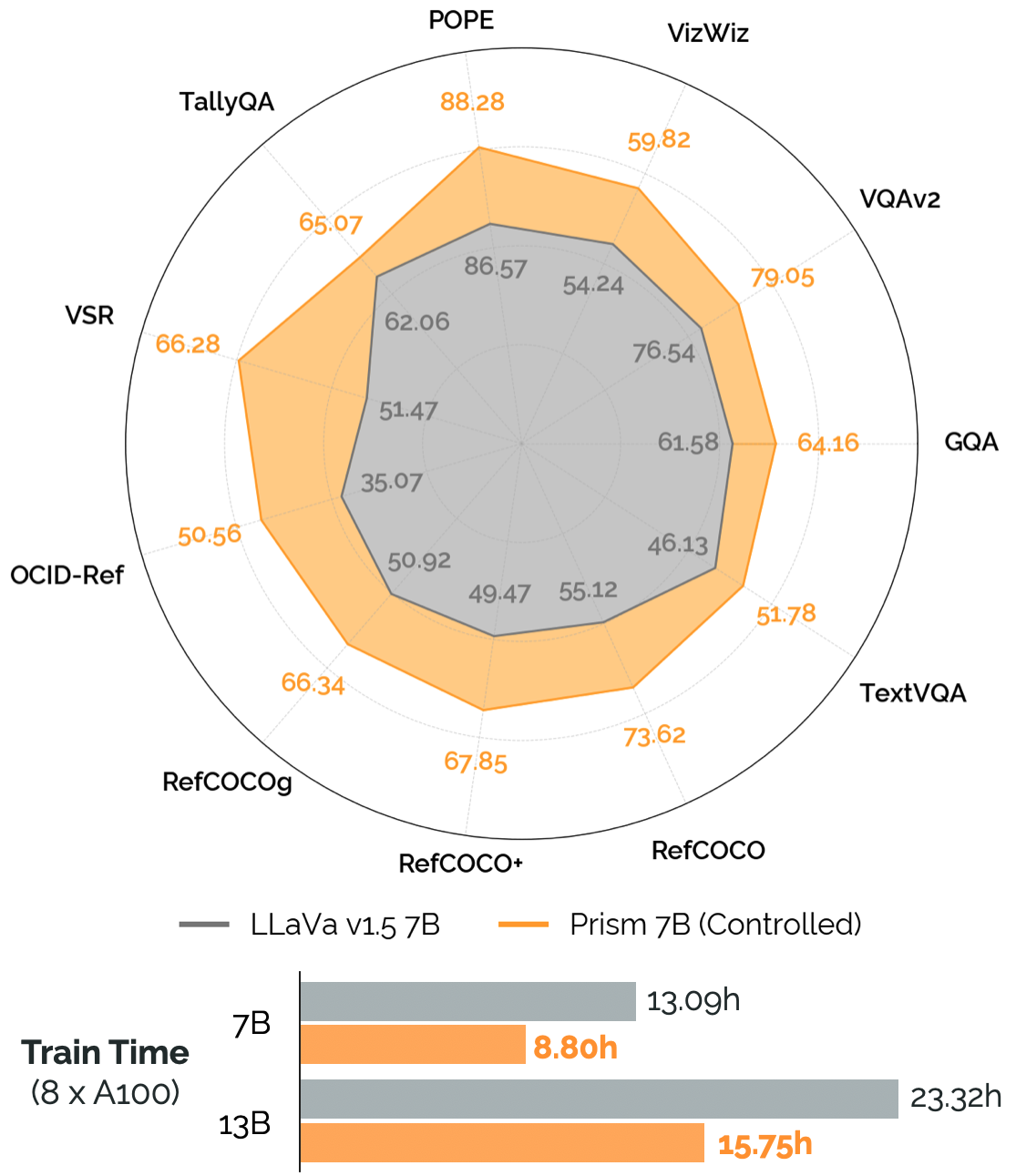
实验结果
研究问题
- RQ1在图像处理、视觉表示和语言模型中,哪些设计选择最强烈地影响 VLM 的性能?
- RQ2多阶段训练是否必要,单阶段训练是否可以更高效地达到相当或更好的结果?
- RQ3 fused 视觉主干与集成是否在各任务中提升 VLM 能力?
- RQ4基础 LMs(如 Llama-2)在 VLMs 中是否优于指令微调的 LMs,使用语言数据的安全性影响如何?
- RQ5训练时间和多样数据源如何影响下游性能?
主要发现
- 单阶段训练在保持或提升性能的同时,显著降低计算成本 20-25%。
- 在初始训练之外对视觉主干进行微调会降低性能,尤其是在定位任务上。
- 融合 DINOv2 与 SigLIP 的视觉表示可以提升性能,通常 DINOv2 + SigLIP 最为有效。
- 基础语言模型(如 Llama-2)在 VLM 中可匹配或超过指令微调的 LM,且幻觉现象更少;语言数据的安全性数据有助于保障。
- 将图像分辨率提高到 336px 或 384px 可以显著提升性能,但计算成本也较高。
- 将 DINOv2 与 SigLIP 或 CLIP/SigLIP 特征进行集成,在定位和挑战任务上获得明显收益;在某些设置中,简单的图像等比缩放可优于信箱填充。
- 增加多样数据源(LVIS-Instruct-4V、LRV-Instruct)可带来性能提升,其中 LRV-Instruct 提供显著改进。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。