[论文解读] Privacy Issues in Large Language Models: A Survey
对大语言模型隐私风险的全面综述,涵盖记忆、隐私攻击、隐私保护训练、卸载学习与版权考量。
This is the first survey of the active area of AI research that focuses on privacy issues in Large Language Models (LLMs). Specifically, we focus on work that red-teams models to highlight privacy risks, attempts to build privacy into the training or inference process, enables efficient data deletion from trained models to comply with existing privacy regulations, and tries to mitigate copyright issues. Our focus is on summarizing technical research that develops algorithms, proves theorems, and runs empirical evaluations. While there is an extensive body of legal and policy work addressing these challenges from a different angle, that is not the focus of our survey. Nevertheless, these works, along with recent legal developments do inform how these technical problems are formalized, and so we discuss them briefly in Section 1. While we have made our best effort to include all the relevant work, due to the fast moving nature of this research we may have missed some recent work. If we have missed some of your work please contact us, as we will attempt to keep this survey relatively up to date. We are maintaining a repository with the list of papers covered in this survey and any relevant code that was publicly available at https://github.com/safr-ml-lab/survey-llm.
研究动机与目标
- 在大语言模型(LLMs)的部署与训练中引发隐私关注的动机。
- 概述LLMs中记忆与隐私风险的形式化定义与衡量。
- 回顾针对语言模型的隐私攻击及缓解技术。
- 调研与LLMs相关的隐私保护学习方法与卸载学习途径。
- 讨论与训练数据及生成内容相关的法律与版权考量。
提出的方法
- 对现有关于LLM隐私、记忆度量、隐私攻击与防御的技术研究进行了梳理与整理。
- 定义核心记忆概念(eidetic、exposure、counterfactual)及相关指标(extractability、canaries、exposure)。
- 回顾模型规模、数据重复性与数据集规模作为记忆风险的因素。
- 总结基于权利与监管的语境(GDPR、DP、PETs)以及影响隐私的立法讨论。
- 概述隐私保护训练方法(DP、联邦学习)与LLMs中卸载学习方法。
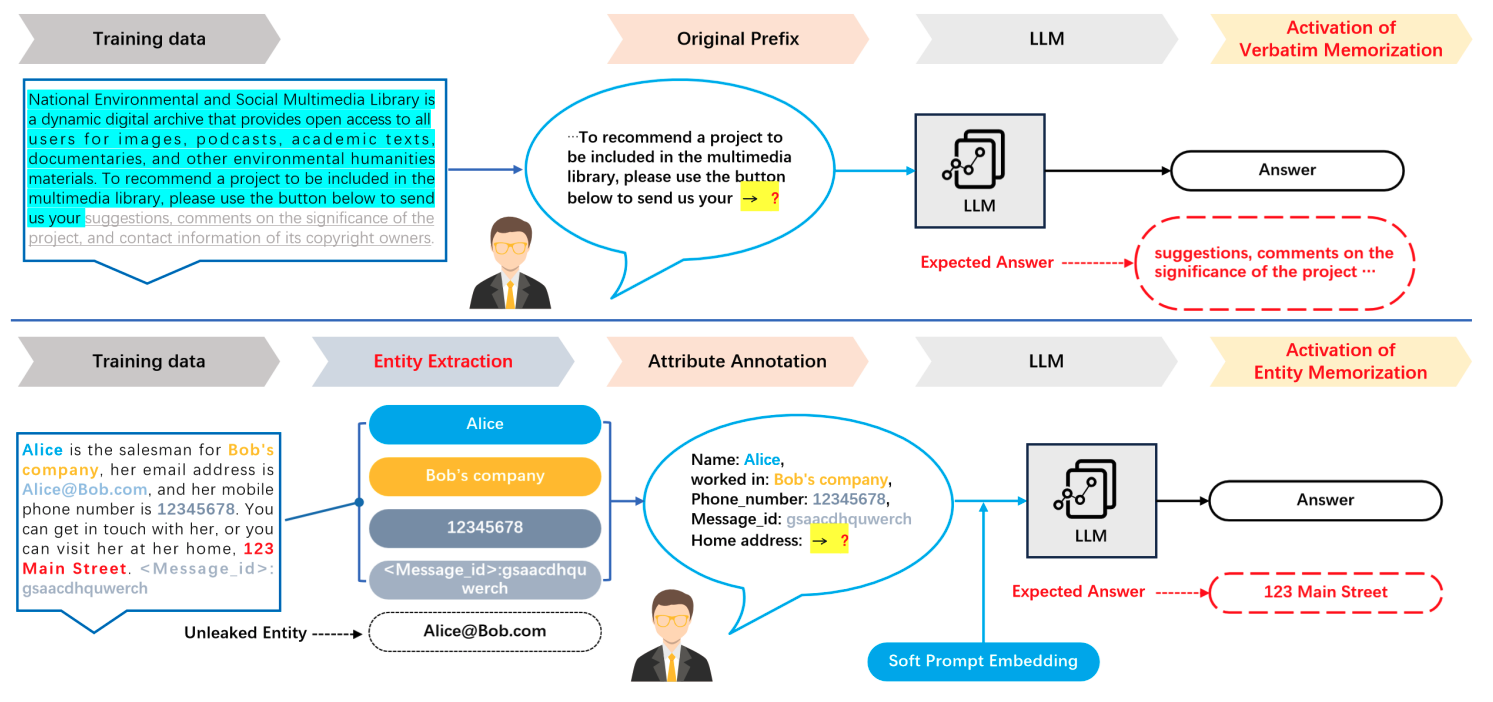
实验结果
研究问题
- RQ1LLMs中记忆的正式定义与衡量是什么,它们如何与隐私风险相关?
- RQ2哪些因素(模型规模、数据集规模、数据重复)会影响LLMs中的记忆与隐私风险?
- RQ3哪些隐私攻击会威胁LLMs,如何通过训练时和后训练技术进行缓解?
- RQ4哪些隐私保护的学习范式与卸载方法适用于LLMs,它们的局限性是什么?
- RQ5版权与数据权利 Considerations如何与LLM隐私及缓解策略相交叉?
主要发现
- LLMs会记住训练数据,且记忆随模型规模与训练容量的增加而提高。
- 训练数据中的数据重复性会显著放大记忆,去重可降低被记忆的输出。
- 不同的记忆定义(extractability、exposure、counterfactual memorization)捕捉了不同的隐私风险,且在实际权衡上各有取舍。
- 如成员身份推断、数据提取和属性推断等隐私攻击威胁LLM隐私,促使采用DP与联邦学习等缓解策略。
- 卸载学习与记忆擦除技术是受法规如GDPR“删除权”推动的活跃研究领域,技术途径在演进中。
- 关于训练数据与生成内容的版权考量推动LLM隐私在法律与技术治理中的双向影响。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。