[论文解读] PromptBench: A Unified Library for Evaluation of Large Language Models
PromptBench 是一个统一的 Python 库,用于在提示、数据集、对抗性提示、动态协议和分析工具等方面评估大语言模型(LLMs)。
The evaluation of large language models (LLMs) is crucial to assess their performance and mitigate potential security risks. In this paper, we introduce PromptBench, a unified library to evaluate LLMs. It consists of several key components that are easily used and extended by researchers: prompt construction, prompt engineering, dataset and model loading, adversarial prompt attack, dynamic evaluation protocols, and analysis tools. PromptBench is designed to be an open, general, and flexible codebase for research purposes that can facilitate original study in creating new benchmarks, deploying downstream applications, and designing new evaluation protocols. The code is available at: https://github.com/microsoft/promptbench and will be continuously supported.
研究动机与目标
- 动机:需要一个统一、可扩展的评估框架来评估 LLM 的能力与安全风险。
- 提供一个以研究为导向的模块化库,支持多样的模型、数据集、提示和评估协议。
- 通过开源平台推动对提示工程、对抗性提示攻击和动态评估的探索。
提出的方法
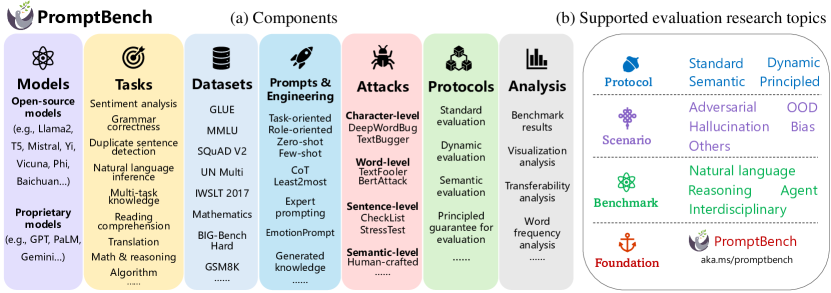
- 引入一个模块化的 Python 库,包含模型、数据集、提示、对抗性提示、动态评估和分析工具等组件。
- 提供统一的 LLMModel 接口和 DatasetLoader,便于构建管道。
- 结合四种提示类型,以及一个 Prompt 接口和六种提示工程方法,以实现灵活的实验。
- 整合七种对抗性提示攻击类型和多种评估协议,包括动态评估和语义评估。
- 提供排行榜和可扩展的分析工具,用于结果解释和比较。
- 开源、附带文档和教程,以支持社区贡献。
实验结果
研究问题
- RQ1如何通过一个统一、可扩展的框架,在提示、任务和协议之间简化对多样化 LLM 的全面评估?
- RQ2在标准化库中,提示工程和对抗性提示在评估 LLM 稳健性方面起什么作用?
- RQ3相比静态推理设置,动态与语义评估协议是否能提供更稳健的基准?
- RQ4PromptBench 在帮助研究人员构建、分享和比较跨模型与数据集的评估管线方面的支持程度如何?
主要发现
- PromptBench 在模块化管线中支持广泛的模型、数据集、任务、提示和评估协议。
- 该库包含对抗性提示攻击和提示工程技术,用于研究稳健性和提示效果。
- 整合动态与语义评估能力,以解决数据污染和超越直接推理的稳健性问题。
- 三个排行榜(对抗性提示攻击、提示工程、动态评估)便于结果比较。
- 该框架强调以研究为导向的可扩展性与通过开源代码和文档实现的开放协作。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。