[论文解读] RAFT: Adapting Language Model to Domain Specific RAG
RAFT 将领域定制的 LLMs 训练用于在开卷、领域内设置中执行检索增强生成,通过包含干扰项和带引用的思维链来提升问答在生物医学、通用问答和 API 文档数据集上的表现。
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a "open-book" in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
研究动机与目标
- Motivate adapting pre-trained LLMs to domain-specific retrieval-augmented generation (RAG).
- Propose a fine-tuning recipe that trains models to ignore irrelevant retrieved documents while citing correct passages.
- Show that including distractors and reasoning improves in-domain RAG performance.
- Demonstrate robustness to varying numbers of retrieved documents and test-time distractors across multiple datasets.
提出的方法
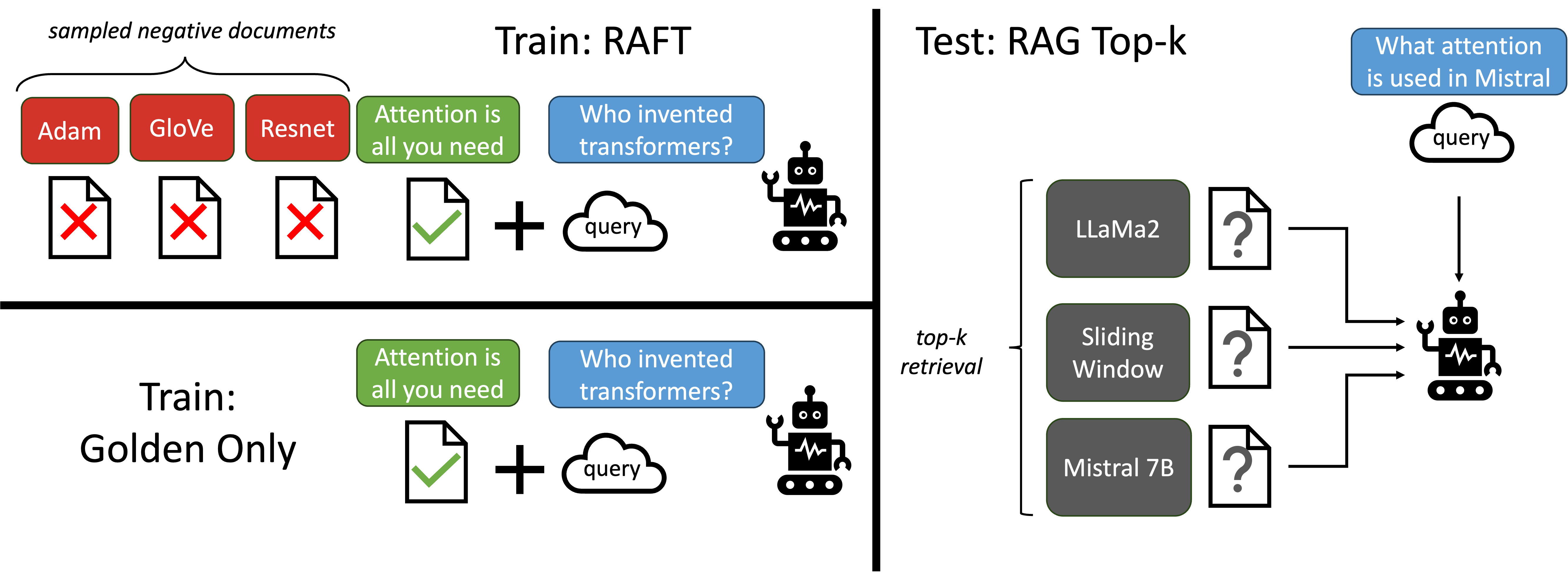
- Introduce RAFT as a retrieval-aware fine-tuning strategy that uses questions, a set of retrieved documents, and a chain-of-thought style answer with citations.
- Create training data where each example has a question Q, a set of documents Dk, and an answer A*, with oracle D* and distractors Di.
- In P fraction of data, include the oracle document with distractors; in (1-P) fraction, omit the oracle to encourage memorization from context.
- Fine-tune the model using supervised fine-tuning (SFT) to generate A* from Q and Dk, with CoT reasoning and citations.
- Demonstrate that RAFT is independent of the retriever and improves RAG performance in-domain.
- Study the impact of the number of distractors k and the proportion P of oracle contexts during training and testing.

实验结果
研究问题
- RQ1How can supervised fine-tuning be adapted to incorporate domain-specific retrieved documents for open-book QA?
- RQ2Does training with distractors and CoT reasoning improve in-domain RAG performance compared to standard DSF or DSF+RAG baselines?
- RQ3How do the number of distractors and the presence/absence of oracle context during training/test affect performance across domains?
主要发现
- RAFT consistently improves domain-specific RAG performance across PubMed, HotpotQA, and Gorilla datasets.
- Compared with baselines, RAFT achieves notable gains, e.g., up to 35.25% on HotpotQA and 76.35% on Torch Hub evaluation.
- Incorporating Chain-of-Thought (CoT) reasoning significantly enhances training robustness and accuracy on several datasets.
- Training with a mix of oracle and distractor documents improves robustness to varying test-time document counts.
- RAFT improves over DSF with and without RAG, and often outperforms a larger model like GPT-3.5+RAG in the same settings.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。