[论文解读] ReactionT5: a large-scale pre-trained model towards application of limited reaction data
ReactionT5 是一种两阶段的预训练 Transformer(基于 T5),在化合物和开放反应数据上进行预训练,以便在有限微调数据下实现产率与产物预测;其性能具有竞争力,泛化能力良好,尤其是在恢复未分类 ORD 化合物后。
Transformer-based deep neural networks have revolutionized the field of molecular-related prediction tasks by treating molecules as symbolic sequences. These models have been successfully applied in various organic chemical applications by pretraining them with extensive compound libraries and subsequently fine-tuning them with smaller in-house datasets for specific tasks. However, many conventional methods primarily focus on single molecules, with limited exploration of pretraining for reactions involving multiple molecules. In this paper, we propose ReactionT5, a novel model that leverages pretraining on the Open Reaction Database (ORD), a publicly available large-scale resource. We further fine-tune this model for yield prediction and product prediction tasks, demonstrating its impressive performance even with limited fine-tuning data compared to traditional models. The pre-trained ReactionT5 model is publicly accessible on the Hugging Face platform.
研究动机与目标
- 推动需要适用于多分子反应的可扩展预训练模型的需求,而非仅限单分子目标。
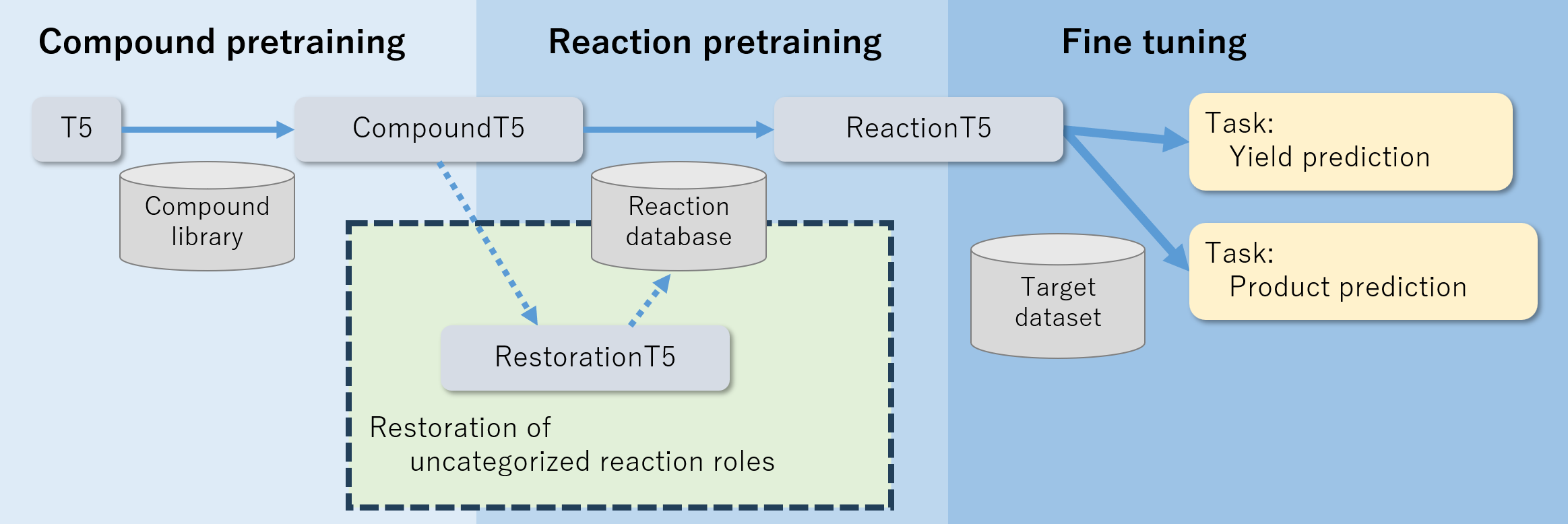
- 开发一个两阶段预训练流程(CompoundT5 然后 ReactionT5),使用 ZINC 与 ORD 数据。
- 展示该模型在有限微调数据下进行产物与得率预测的有效性。
提出的方法
- 将反应任务表述为文本到文本的问题,使用 T5 架构。
- 阶段 1:化合物预训练以创建 CompoundT5,使用 ZINC 的 SMILES 并进行跨度屏蔽语言建模。
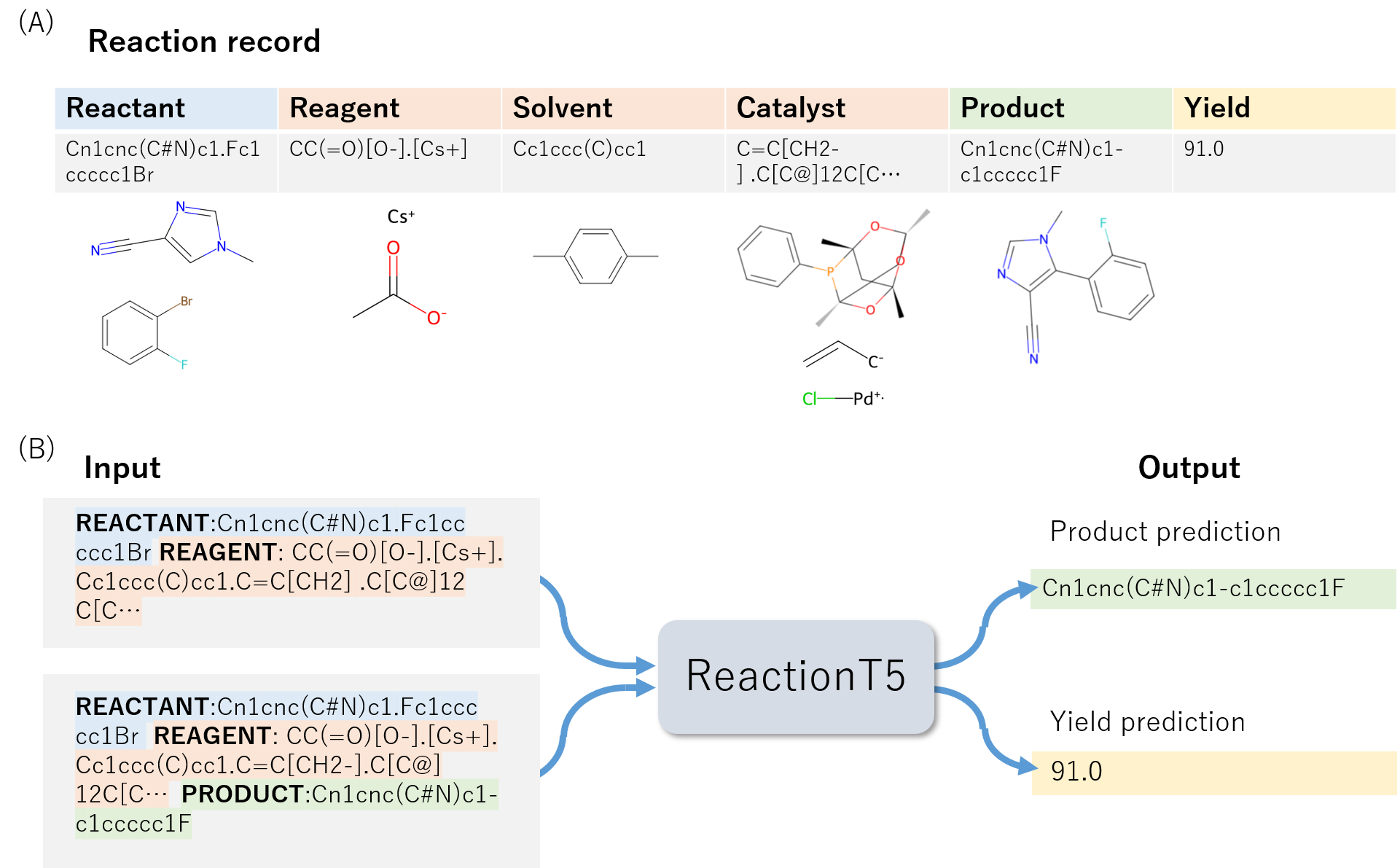
- 阶段 2:反应预训练以创建 ReactionT5,使用 ORD 数据并覆盖六个反应角色(反应物、试剂、溶剂、催化剂、产物、产率)。
- 引入 RestorationT5,用于对未分类的 ORD 化合物进行分类并恢复缺失的角色。
- 在目标数据集上微调 ReactionT5(对产物预测使用 USPTO,对得率预测使用 Buchwald–Hartwig C–N 交叉偶联)。
- 对产物预测采用大小为 10 的光束搜索,并优化长度约束以提高准确性。
实验结果
研究问题
- RQ1两阶段预训练 Transformer(CompoundT5 然后 ReactionT5)是否可以在小型目标数据集上改进产物和得率预测?
- RQ2恢复未分类 ORD 化合物是否在最小微调下提升产物预测性能?
- RQ3与传统模型相比,ReactionT5 在零-shot 和低数据微调情景下的表现如何?
主要发现
| 模型 | 训练集 | 测试集 | Top1 | Top2 | Top3 | Top5 | 无效性 |
|---|---|---|---|---|---|---|---|
| Seq-to-seq | USPTO | USPTO | 80.3 | 84.7 | 86.2 | 87.5 | - |
| WLDN | USPTO | USPTO | 85.6 | 90.5 | 92.8 | 93.4 | - |
| Mol Transformer | USPTO | USPTO | 88.8 | 92.6 | - | 94.4 | - |
| T5Chem | USPTO | USPTO | 90.4 | 94.2 | - | 96.4 | - |
| CompoundT5 | USPTO | USPTO | 88.0 | 92.4 | 93.9 | 95.0 | 7.5 |
| ReactionT5(ORD) | - | USPTO | 0.0 | 0.0 | 0.0 | 0.0 | 0.6 |
| ReactionT5(ORD) | USPTO200 | USPTO | 0.0 | 0.0 | 0.0 | 0.0 | 4.2 |
| ReactionT5(restored ORD) | - | USPTO | 0.0 | 0.0 | 0.0 | 0.0 | 1.1 |
| ReactionT5(restored ORD) | USPTO200 | USPTO | 85.5 | 91.7 | 93.5 | 94.9 | 12.0 |
- 在恢复未分类 ORD 数据后,基于 ORD 的 ReactionT5 在使用有限的 USPTO 数据进行微调时仍能实现具有竞争力的产物预测。
- 微调 ReactionT5 仅需 30–200 个 USPTO 反应即可在产物预测上达到 Top1 >80%,接近在全数据上训练的模型。
- ReactionT5 在 ORD 上训练在得率预测任务上表现出较强的泛化能力,特别是在外部测试集 Test 1–4 上。
- RestorationT5 在最小额外微调下提升基于 ORD 的产物预测。
- 零-shot 的 ReactionT5 在得率预测任务上可超越某些在 30% 数据上训练的基线模型。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。