QUICK REVIEW
[论文解读] Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
Bonan Min, Hayley Ross|arXiv (Cornell University)|Nov 1, 2021
Topic Modeling参考文献 182被引用 161
一句话总结
对大型预训练语言模型(PLMs)如何通过 pre-train/fine-tune、prompting、text generation 完成 NLP 的综述,以及用于数据生成以进行增广和未来方向。
ABSTRACT
Large, pre-trained transformer-based language models such as BERT have drastically changed the Natural Language Processing (NLP) field. We present a survey of recent work that uses these large language models to solve NLP tasks via pre-training then fine-tuning, prompting, or text generation approaches. We also present approaches that use pre-trained language models to generate data for training augmentation or other purposes. We conclude with discussions on limitations and suggested directions for future research.
研究动机与目标
- 解释 NLP 中向大型预训练变换模型转变及三大范式(pre-train then fine-tune、prompt-based learning、NLP as text generation)。
- 总结 PLMs 如何用于解析、信息抽取(IE)、问答(QA)、文本生成之外的任务,以及情感分析等任务。
- 讨论数据生成方法及其局限性,并概述未来的研究方向。
提出的方法
- 描述三种基于 PLM 的范式:pre-train then fine-tune、prompting、text generation,以及数据生成的补充。
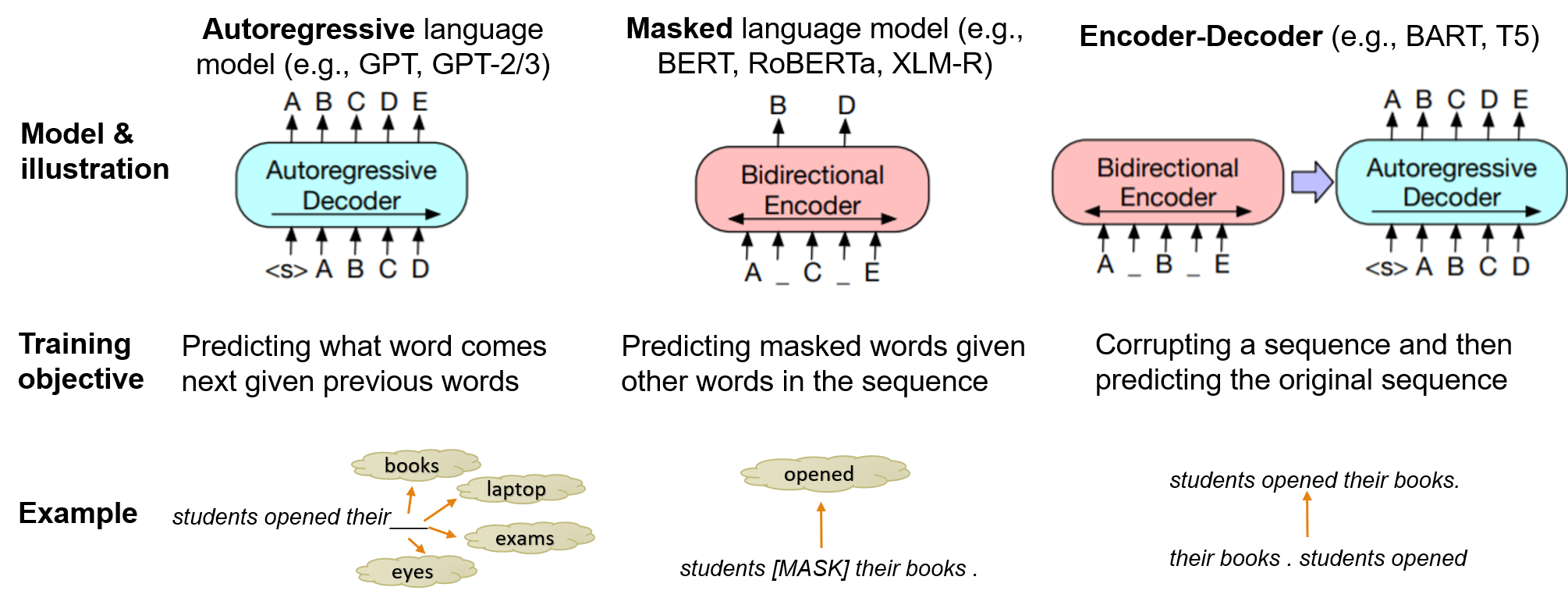
- 详述模型类别(自回归、掩码语言模型、编码器-解码器)及典型的预训练目标。
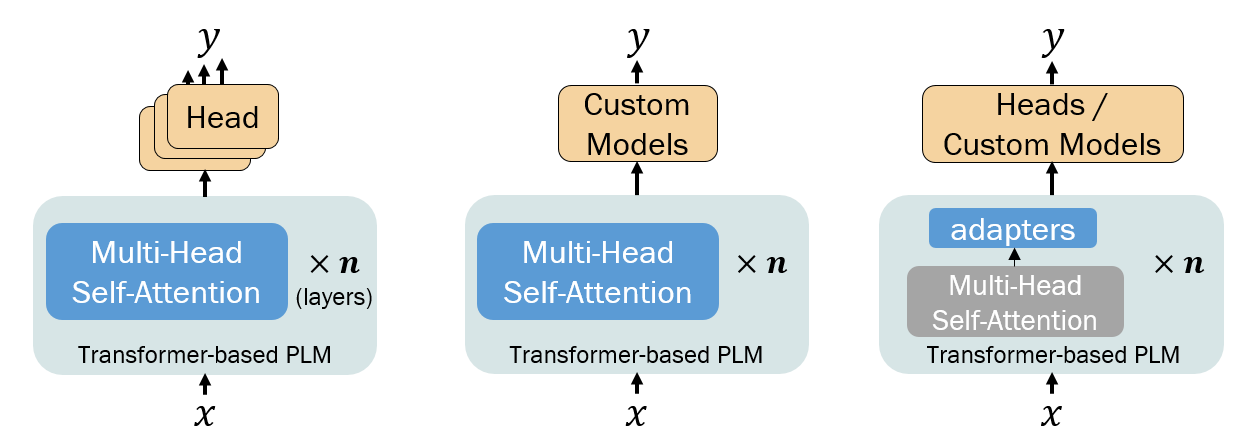
- 总结微调策略,包括全微调、adapter 基于方法以及高效微调方法。
- 讨论数据来源、规模效应和领域特定的预训练。
- 回顾提示设计方法及其在少样本学习和任务探测中的益处。
实验结果
研究问题
- RQ1解决 NLP 任务的主导 PLM 基于范式有哪些,它们在方法和优化上有何不同?
- RQ2模型架构、预训练数据和微调策略如何影响各类 NLP 任务的性能?
- RQ3在利用 PLMs 进行少样本学习和任务对齐时,prompting 扮演怎样的角色?
- RQ4PLMs 如何用于生成数据或为 NLP 任务的训练进行增广,以及其局限性?
- RQ5PLMs 在 NLP 领域的当前局限性与未来方向是什么?
主要发现
- PLMs 通过三大范式:pre-train then fine-tune、prompt-based learning、NLP as text generation,在多样化的 NLP 任务中实现最先进的性能。
- 自回归、掩码语言模型、编码器-解码器 PLMs 在训练目标和对不同任务类型的适用性上不同。
- 微调策略从全模型微调到适配器以及参数高效方法,能够缓解遗忘并降低训练成本。
- 数据规模和质量显著影响收益,模型大小和数据集大小常常驱动性能提升;数据清洗至关重要。
- prompting 使少样本学习成为可能并更好地与预训练目标对齐,而指令驱动或演示驱动的 prompts 在不进行大规模微调的情况下提升任务性能。
- 通过 PLMs 进行数据生成是一种互补的方法,用于创建 silver data 或辅助上下文以支持目标任务。
- 局限性包括领域不匹配、可扩展性以及可能反映训练数据偏见的潜在不准确性;未来方向包括提高效率、适应性和鲁棒性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。