[论文解读] Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey
本文综述了自2019–2024年以来大规模分布式深度学习的资源分配与工作负载调度策略,包括对大模型训练的案例研究。
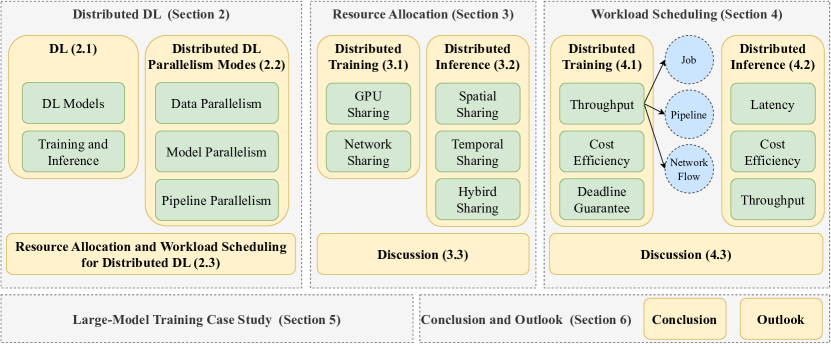
With rapidly increasing distributed deep learning workloads in large-scale data centers, efficient distributed deep learning framework strategies for resource allocation and workload scheduling have become the key to high-performance deep learning. The large-scale environment with large volumes of datasets, models, and computational and communication resources raises various unique challenges for resource allocation and workload scheduling in distributed deep learning, such as scheduling complexity, resource and workload heterogeneity, and fault tolerance. To uncover these challenges and corresponding solutions, this survey reviews the literature, mainly from 2019 to 2024, on efficient resource allocation and workload scheduling strategies for large-scale distributed DL. We explore these strategies by focusing on various resource types, scheduling granularity levels, and performance goals during distributed training and inference processes. We highlight critical challenges for each topic and discuss key insights of existing technologies. To illustrate practical large-scale resource allocation and workload scheduling in real distributed deep learning scenarios, we use a case study of training large language models. This survey aims to encourage computer science, artificial intelligence, and communications researchers to understand recent advances and explore future research directions for efficient framework strategies for large-scale distributed deep learning.
研究动机与目标
- 系统性地评估大规模分布式DL的资源分配与工作负载调度框架。
- 分析跨资源类型(GPU、网络)及调度粒度(作业、流水线、网络流)的挑战。
- 比较现有技术并提供见解以指导数据中心的实际部署。
- 通过对大模型分布式训练的案例研究来说明应用。
- 提出未来的研究方向,以提高效率和可扩展性。
提出的方法
- 对2019–2024年在分布式DL资源管理与调度方面的文献进行系统性综述。
- 按资源类型(GPU共享、网络共享)和调度粒度(作业、流水线、coflow)对策略进行分类。
- 围绕训练和推理工作流及多重性能目标组织分析。
- 提供一个关于大模型分布式训练的案例研究以展示实际应用。
- 提供对挑战的综合分析和关键见解,以指导未来研究。
实验结果
研究问题
- RQ1在大型分布式DL的资源分配与工作负载调度中,主要挑战是什么?
- RQ2有哪些GPU共享和网络带宽共享策略,它们在调度粒度上有何差异?
- RQ3如何将这些框架策略在实践中应用,以提升数据中心的训练与推理性能?
- RQ4从对2019年至2024年的文献调研中出现了哪些洞见与未来方向?
主要发现
- 该综述全面映射了大规模分布式DL在训练与推理中的资源分配与工作负载调度框架。
- 它突出了GPU共享、网络带宽共享以及在作业、流水线和网络流层级上的调度等关键挑战。
- 它比较了相关综述并通过强调联合计算-通信优化来填补空白。
- 它提供了一个关于大模型分布式训练的案例研究,以展示数据中心的实际应用。
- 它识别出不足并提出面向高效框架策略的未来研究方向。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。