[论文解读] RiNALMo: General-Purpose RNA Language Models Can Generalize Well on Structure Prediction Tasks
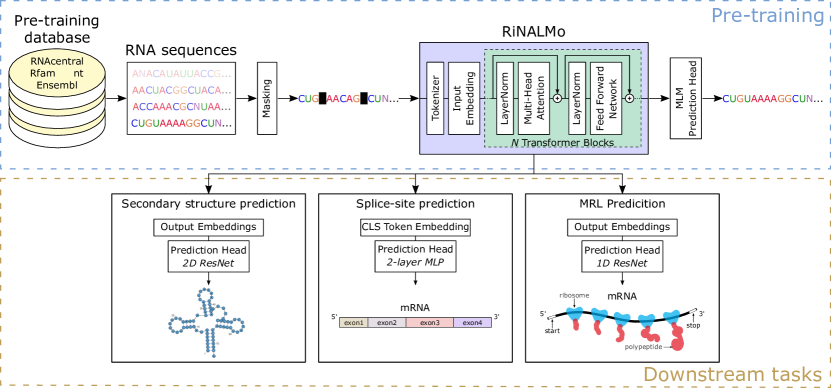
RiNALMo 是一个650M参数的RNA语言模型,在36M个ncRNA序列上进行预训练,在RNA结构和功能任务上表现出强泛化能力,超越现有模型,覆盖包括未见RNA家族在内的多个数据集。
While RNA has recently been recognized as an interesting small-molecule drug target, many challenges remain to be addressed before we take full advantage of it. This emphasizes the necessity to improve our understanding of its structures and functions. Over the years, sequencing technologies have produced an enormous amount of unlabeled RNA data, which hides a huge potential. Motivated by the successes of protein language models, we introduce RiboNucleic Acid Language Model (RiNALMo) to unveil the hidden code of RNA. RiNALMo is the largest RNA language model to date, with 650M parameters pre-trained on 36M non-coding RNA sequences from several databases. It can extract hidden knowledge and capture the underlying structure information implicitly embedded within the RNA sequences. RiNALMo achieves state-of-the-art results on several downstream tasks. Notably, we show that its generalization capabilities overcome the inability of other deep learning methods for secondary structure prediction to generalize on unseen RNA families.
研究动机与目标
- 利用大规模非标记RNA数据来学习通用的RNA表征。
- 在RNA为中心的Transformer编码器上进行预训练,结合现代架构改进。
- 在多样化的下游任务上评估RiNALMo,以评估结构与功能的泛化能力。
- 展示跨家族的泛化能力,在未见RNA家族上进行评估。
- 公开代码以促进更广泛的应用与可重复性。
提出的方法
- 将RiNALMo(650M参数)作为BERT样式的编码器进行预训练,使用掩码语言模型,在来自RNAcentral、Rfam、nt和Ensembl的36M个ncRNA序列上训练。
- 使用33个Transformer块,采用RoPE位置编码、SwiGLU激活、FlashAttention-2,每个块20个注意力头。
- 将输入长度限制为1024个标记,并以15%的损坏程度进行训练(80%掩码、10%随机标记、10%未改动),使用交叉熵损失。
- 用1280维嵌入向量表示序列;在前置CLS标记、后置EOS标记;在下游任务上端到端微调,使用简单的预测头。
- 通过附加一个基于ResNet的简单预测器来评估结构任务的嵌入,以及用于剪接位点和核糖体装载任务的MLP头来评估学习到的嵌入。
实验结果
研究问题
- RQ1RiNALMo是否能够对在训练中未见的RNA家族进行泛化,以进行二级结构预测?
- RQ2与现有RNA语言模型和传统方法相比,RiNALMo在多物种剪接位点预测上的表现如何?
- RQ3RiNALMo是否能够实现准确的平均核糖体装载预测,并且从随机起源训练泛化到人类序列?
主要发现
- RiNALMo在跨家族二级结构预测上显著优于其他方法,在大多数测试家族中取得更高的F1分数。
- 在跨家族泛化方面,RiNALMo在九个家族中有八个超过基于热力学和深度学习的基线(端粒酶RNA是一个显著的例外)。
- 在多物种剪接位点预测方面,RiNALMo在鱼、果蝇、植物和线虫数据集上实现了最先进的F1分数。
- 在平均核糖体装载预测中,RiNALMo在Random7600和Human7600数据集上取得了比Uni-RNA、RNA-FM和Optimus 5-Prime更高的R^2分数。
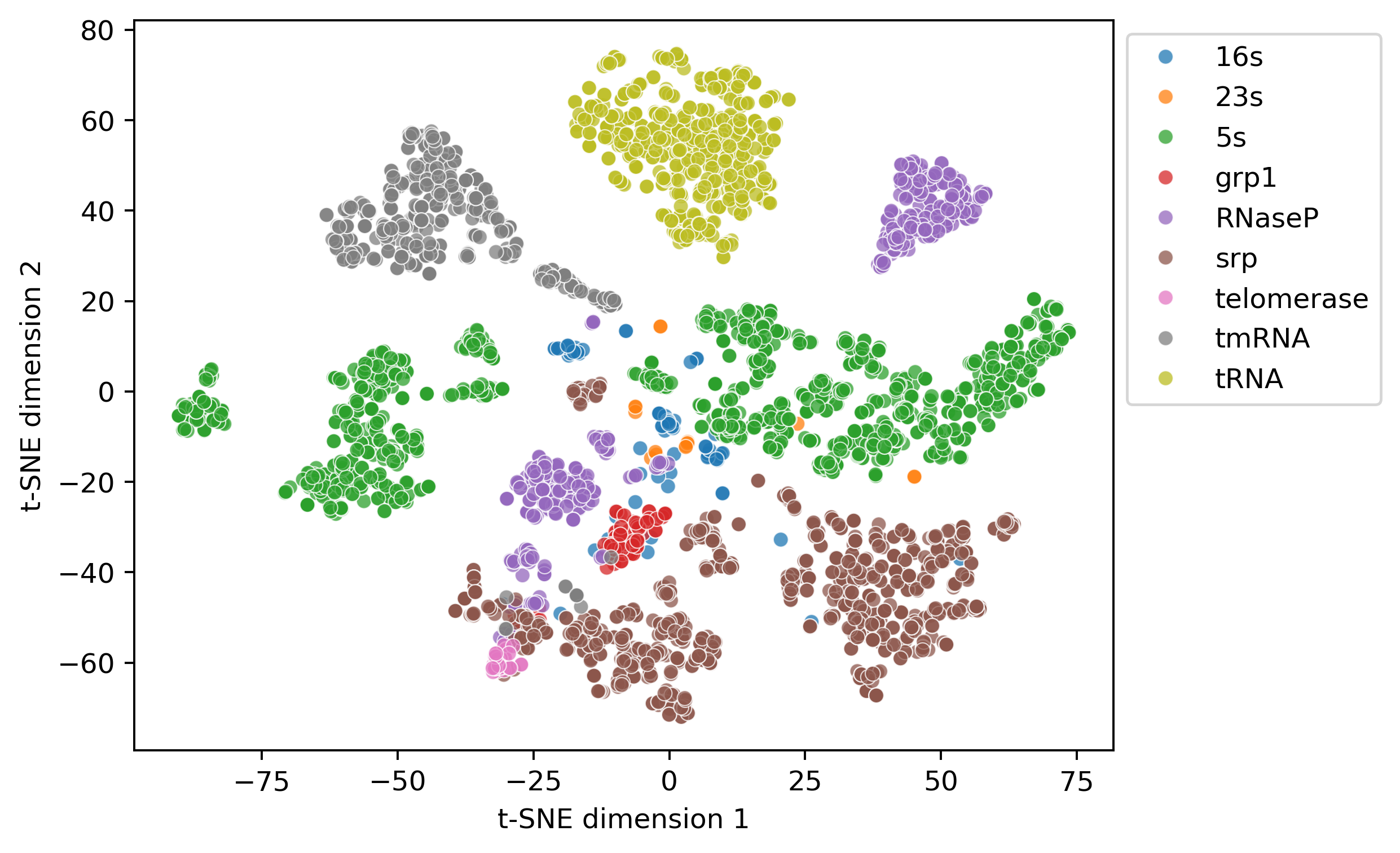
- RiNALMo的跨家族结构嵌入在t-SNE可视化中显示出按RNA家族的清晰聚类,表明嵌入中包含丰富的结构信息。
- RiNALMo的跨家族二级结构平均F1分数为0.72,高于RNAstructure(0.59)和CONTRAfold(0.61)及其他基线(表2)。
- 在供体/受体剪接位点预测中,RiNALMo在鱼、果蝇、植物、线虫上的平均F1分数分别为97.70、96.11、96.25和95.63。
- RiNALMo的剪接位点结果在所报告的物种分割(表3)上超越了SpliceBERT、Uni-RNA、RNA-FM、Spliceator。
- RiNALMo通过在随机起源序列上训练仍能在人体UTR MRL数据上取得接近最先进水平的性能,显示出稳健的泛化能力(表4中的Random7600与Human7600对比)。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。