[论文解读] RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
本文展示了来自 AI 反馈的强化学习 (RLAIF) 在三个文本生成任务中与 RLHF 相匹配甚至超越,在成本方面往往更低且与人类偏好的一致性相近,并且证明直接使用 AI 奖励可以超越经典的蒸馏方法。
Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences, but gathering high-quality preference labels is expensive. RL from AI Feedback (RLAIF), introduced in Bai et al., offers a promising alternative that trains the reward model (RM) on preferences generated by an off-the-shelf LLM. Across the tasks of summarization, helpful dialogue generation, and harmless dialogue generation, we show that RLAIF achieves comparable performance to RLHF. Furthermore, we take a step towards "self-improvement" by demonstrating that RLAIF can outperform a supervised fine-tuned baseline even when the AI labeler is the same size as the policy, or even the exact same checkpoint as the initial policy. Finally, we introduce direct-RLAIF (d-RLAIF) - a technique that circumvents RM training by obtaining rewards directly from an off-the-shelf LLM during RL, which achieves superior performance to canonical RLAIF. Our results suggest that RLAIF can achieve performance on-par with using human feedback, offering a potential solution to the scalability limitations of RLHF.
研究动机与目标
- 证明 AI 生成的偏好标签可以替代语言模型中的 RLHF 人类标签。
- 在摘要、帮助性对话和无害对话任务中评估 RLAIF,与 RLHF 和 SFT 基线进行对比。
- 探究 AI 标注方法(思考链 CoT、前缀、提示风格)如何影响与人类偏好的对齐。
- 研究 AI 标注器是否可以与策略同等大小,以及直接使用 AI 奖励是否改善 RL 性能。
提出的方法
- 使用 PaLM 2 作为现成的 AI 标注器,对每个任务中候选输出之间的成对偏好进行评分。
- 在 AI 生成的偏好上训练奖励模型(蒸馏的 RLAIF),并用 RM 提供的奖励进行基于 REINFORCE 的 RL。
- 与直接的 RLAIF 进行比较,其中 LLM 直接对输出进行评分以获得 RL 奖励(无奖励模型)。
- 尝试提示变体(基础/详细序言、链式思考推理、上下文示例)以最大化 AI 标注器与人类偏好的对齐。
- 通过 AI 标注器对齐、胜率(人类偏好相对于策略)、无害率(输出的安全性)来评估对齐。
- 在同尺寸 AI 标注器(AI 标注器大小等于策略大小)以及直接 AI 奖励的情况下测试鲁棒性。
- 分析语言模型规模对 AI 标注质量和对齐的影响。
实验结果
研究问题
- RQ1AI 生成的偏好是否在摘要和对话任务中的 RLHF 风格训练中达到与人类偏好相当的表现?
- RQ2RLAIF 是否在可扩展性和成本方面相较于 RLHF 提供优势,而不牺牲人类对齐质量?
- RQ3在强化学习期间直接对 LLM 进行奖励提示是否比将 AI 偏好蒸馏到单独的奖励模型更有效?
- RQ4提示技巧和 AI 标注器大小如何影响与人类偏好的对齐和下游策略质量?
主要发现
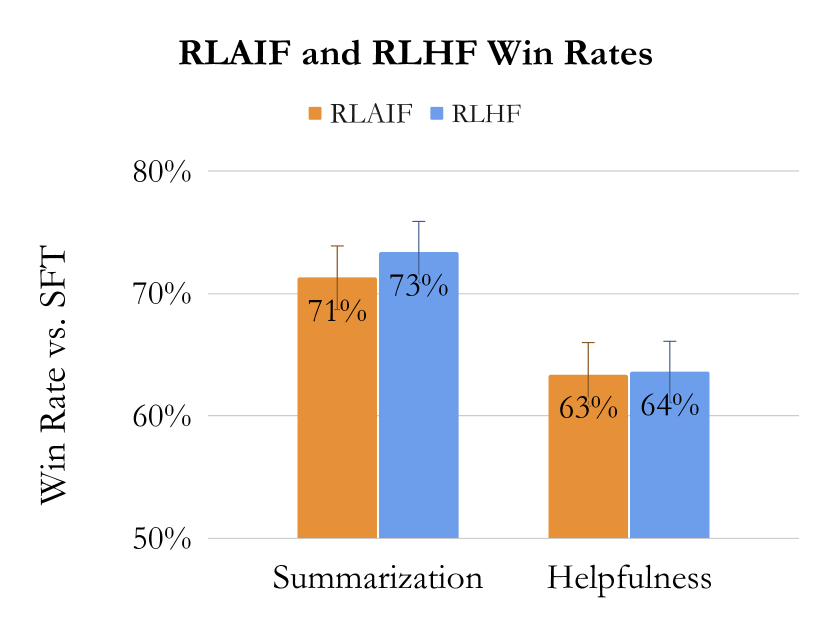
| 模型比较 | 摘要胜率对比 SFT (%) | 帮助性对话胜率对比 SFT (%) | 无害率 (%) |
|---|---|---|---|
| RLAIF vs SFT | 71 | 63 | - |
| RLHF vs SFT | 73 | 64 | - |
| RLAIF vs RLHF | 50 | 52 | - |
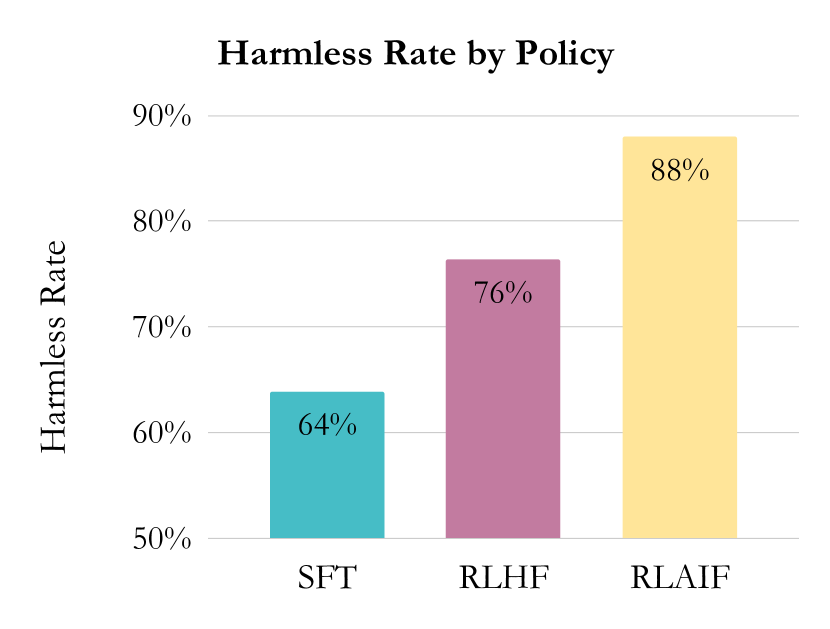
| 无害对话:RLAIF vs RLHF vs SFT | - | - | 88 (RLAIF) / 76 (RLHF) / 64 (SFT) |
- RLAIF 在三个任务(摘要、帮助性对话、无害对话)上实现可比或优于 RLHF 的表现。
- 在摘要和帮助性对话中,RLAIF 与 RLHF 均超越 SFT 基线;RLAIF 与 RLHF 的胜率在统计上没有显著差异。
- 在无害对话方面,RLAIF 达到 88% 的无害率,高于 RLHF(76%)和 SFT(64%)。
- 在 RL 过程中直接对 LLM 进行奖励提示可以超越使用从 AI 偏好蒸馏出的奖励模型的标准 RLAIF 设置。
- 即使 AI 标注器与策略大小相同,RLAIF 也可以优于 SFT(同尺寸 RLAIF)。
- 能够引出链式思考推理的提示技巧通常会改善 AI 标注器的对齐;详细前缀和少量示例提示在不同任务上效果参差不齐。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。