[论文解读] Robust agents learn causal world models
本文证明,在广义分布偏移类下,学习数据生成过程的近似因果模型对于鲁棒自适应既是必要的也是充分的,并且展示了这如何使从自适应策略中进行因果发现成为可能。
It has long been hypothesised that causal reasoning plays a fundamental role in robust and general intelligence. However, it is not known if agents must learn causal models in order to generalise to new domains, or if other inductive biases are sufficient. We answer this question, showing that any agent capable of satisfying a regret bound under a large set of distributional shifts must have learned an approximate causal model of the data generating process, which converges to the true causal model for optimal agents. We discuss the implications of this result for several research areas including transfer learning and causal inference.
研究动机与目标
- 在鲁棒通用智能与域自适应中凸显因果推理的作用。
- 证明在分布偏移下的带悔恨界的自适应意味着需要学习因果模型。
- 在学习因果结构和在干预下实现鲁棒策略之间建立形式等价关系。
- 讨论对迁移学习、因果表征学习和因果发现的含义。
提出的方法
- 使用因果影响图(CIDs)和因果贝叶斯网络(CBNs)对决策任务建模。
- 定义局部干预及局部干预的混合以建模域的偏移。
- 证明在跨域移位的最优策略的祖先的因果图和联合分布可辨识性(定理1)。
- 放宽到对悔恨界策略,并给出带误差界的近似因果模型识别(定理2)。
- 通过显示近似因果模型在干预下可识别悔恨界策略来证明充分性(定理3)。
- 讨论对于迁移学习、自适应智能体和因果推断的解释,并概述使用策略反应的因果发现方法。
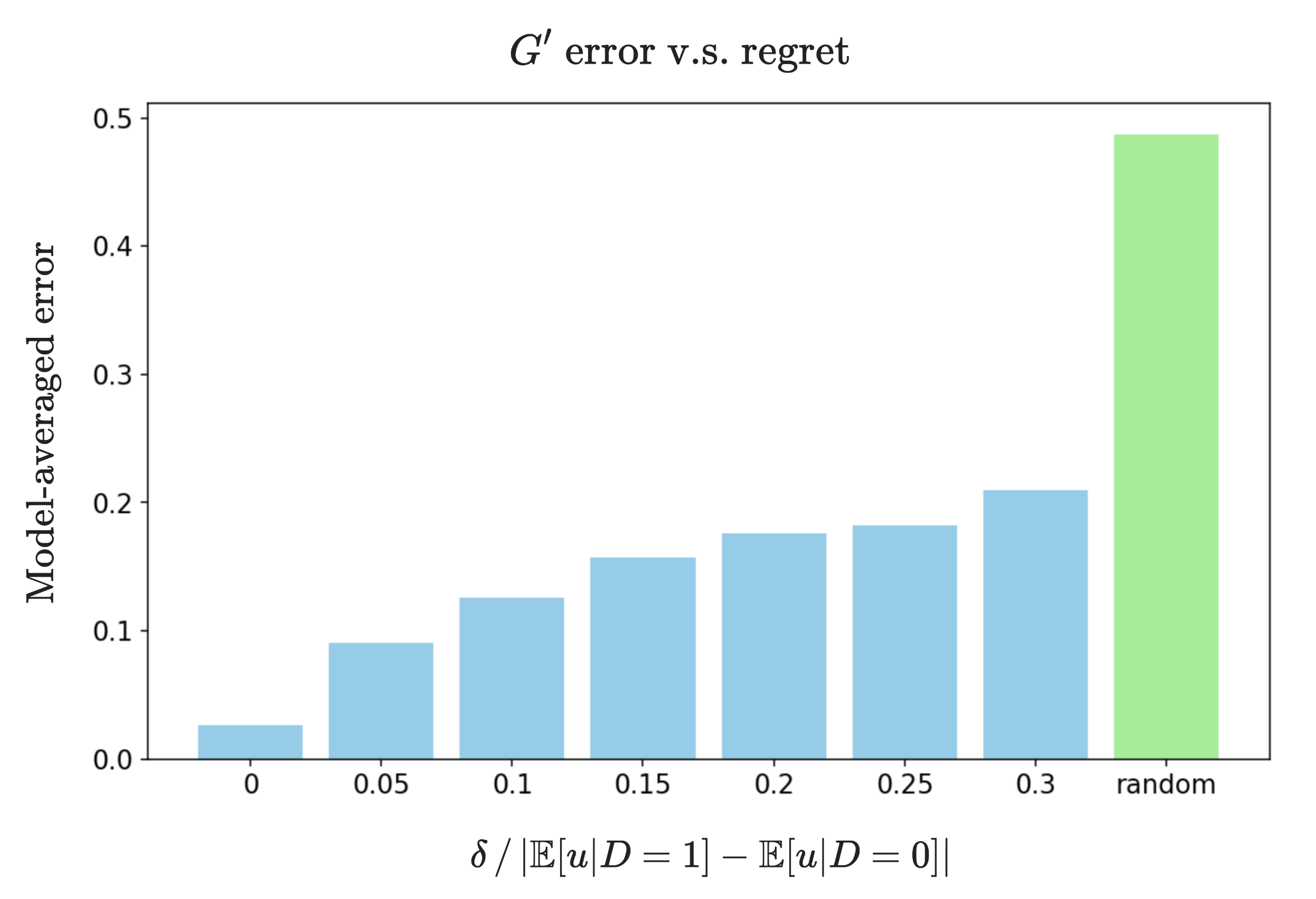
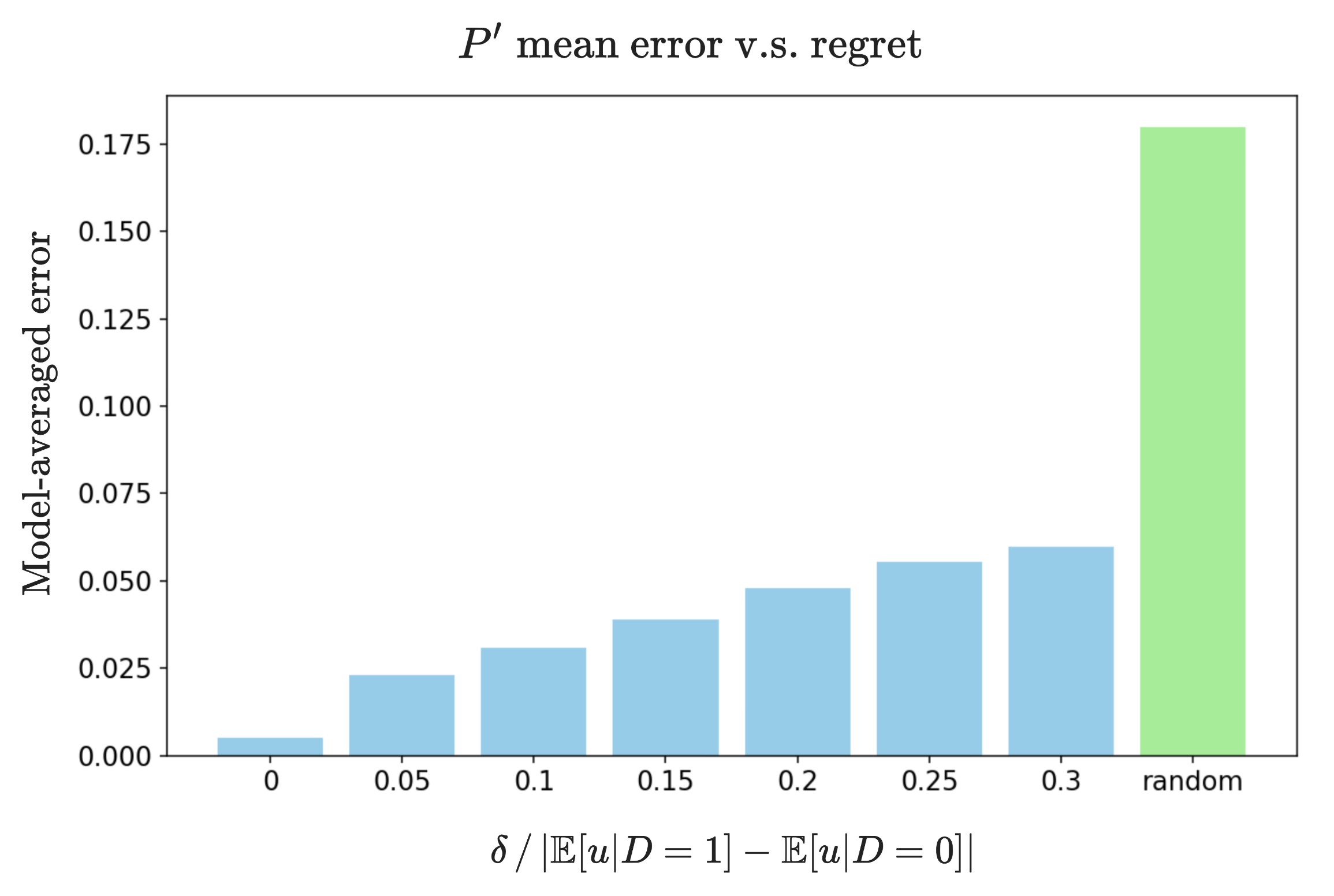
实验结果
研究问题
- RQ1鲁棒自适应对分布偏移是否需要学习环境的因果模型?
- RQ2域偏移下的最优策略是否能识别潜在的因果图及分布?
- RQ3如果策略仅是近似最优(悔恨界),是否仍能恢复近似的因果模型?
- RQ4学习因果世界模型是否足以在各种干预下实现悔恨界策略?
- RQ5这些结果对迁移学习、因果表征学习和因果发现的含义是什么?
主要发现
- 对于几乎所有满足所述假设的因果影响图,跨局部干预的混合中的最优策略能够识别因果图以及对效用祖先的联合分布(定理1)。
- 来自悔恨界策略的近似因果模型可以被识别,参数估计误差与悔恨水平呈线性增长(定理2)。
- 近似因果模型足以在局部干预下识别悔恨界策略(定理3)。
- 因此,学习因果模型在广义的域偏移下的鲁棒自适应方面既是必要的也是充分的。
- 这些结果将域自适应、因果表征学习和因果发现联系起来,表明在多个域上训练的智能体将学习因果世界模型,并实现更广泛的任务泛化。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。