[论文解读] Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
本文提出 FARE,一种对 CLIP 视觉编码器进行无监督对抗微调的方法,在保持原始嵌入的同时提高鲁棒性,使下游 VLM 在不重新训练的情况下实现鲁棒。
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
研究动机与目标
- 解决多模态基础模型中的视觉编码器在对抗攻击下的脆弱性。
- 开发一种无监督微调方案,在保持干净任务性能的同时获得鲁棒的 CLIP 嵌入。
- 确保鲁棒性能够转移到下游的视觉-语言模型(VLM),而无需重新训练它们的组件。
- 将无监督的 FARE 与现有的有监督方法进行比较,并证明整体鲁棒性提升。
提出的方法
- formulated an embedding-based adversarial fine-tuning objective that preserves original CLIP embeddings on clean inputs.
- Defined the FARE loss as the maximized squared distance between the fine-tuned embedding of perturbed images and the original CLIP embedding of clean images.
- Solving the inner maximization with PGD to generate adversarial perturbations during fine-tuning.
- Show that minimizing the embedding discrepancy also preserves cosine similarities used by downstream tasks.
- Replace the original CLIP vision encoder with the robust FARE-CLIP in existing VLMs without retraining their language or integration components.
实验结果
研究问题
- RQ1Can an unsupervised adversarial fine-tuning objective for CLIP’s image encoder produce robust embeddings without degrading clean downstream performance?
- RQ2Does retaining the original embedding behavior while adding robustness enable seamless substitution of CLIP encoders in vision-language models like OpenFlamingo and LLaVA?
- RQ3How does FARE compare to supervised adversarial fine-tuning (TeCoA) in terms of clean accuracy and robustness across zero-shot classification and VLM tasks?
主要发现
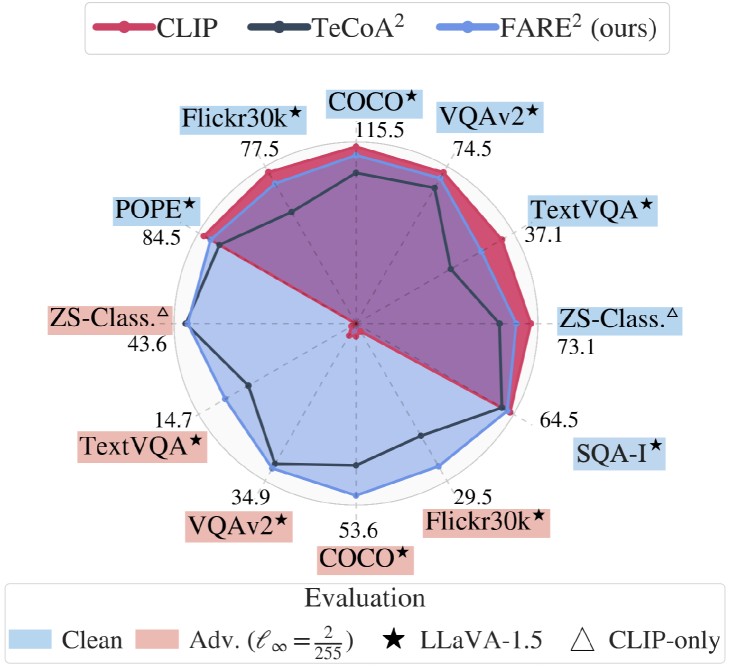
- FARE maintains close alignment to the original CLIP embeddings on clean data, enabling plug-and-play replacement in VLMs without re-training.
- Robustness gains are achieved against l_infinity adversarial perturbations across multiple downstream tasks and VLMs.
- FARE outperforms the supervised TeCoA approach on several zero-shot and VLM evaluation tasks, while preserving clean performance.
- Substituting robust CLIP encoders in VLMs reduces transferability of adversarial images between models and lowers targeted attack success rates.
- FARE also shows favorable outcomes on additional tasks such as hallucination and reasoning benchmarks, compared to TeCoA.

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。