[论文解读] Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
这篇论文认为降低 FLOPs 并不保证更低的延迟,因为内存瓶颈,并引入 Partial Convolution (PConv) 和 FasterNet,一种高速 CNN 家族,在 GPU、CPU 和 ARM 设备上实现更高的 FLOPS 和更快的推理,同时不牺牲准确性。
To design fast neural networks, many works have been focusing on reducing the number of floating-point operations (FLOPs). We observe that such reduction in FLOPs, however, does not necessarily lead to a similar level of reduction in latency. This mainly stems from inefficiently low floating-point operations per second (FLOPS). To achieve faster networks, we revisit popular operators and demonstrate that such low FLOPS is mainly due to frequent memory access of the operators, especially the depthwise convolution. We hence propose a novel partial convolution (PConv) that extracts spatial features more efficiently, by cutting down redundant computation and memory access simultaneously. Building upon our PConv, we further propose FasterNet, a new family of neural networks, which attains substantially higher running speed than others on a wide range of devices, without compromising on accuracy for various vision tasks. For example, on ImageNet-1k, our tiny FasterNet-T0 is $2.8 imes$, $3.3 imes$, and $2.4 imes$ faster than MobileViT-XXS on GPU, CPU, and ARM processors, respectively, while being $2.9\%$ more accurate. Our large FasterNet-L achieves impressive $83.5\%$ top-1 accuracy, on par with the emerging Swin-B, while having $36\%$ higher inference throughput on GPU, as well as saving $37\%$ compute time on CPU. Code is available at \url{https://github.com/JierunChen/FasterNet}.
研究动机与目标
- 突出现有快速网络中 FLOPs 与实际延迟之间的不匹配。
- 引入 Partial Convolution (PConv) 来减少冗余计算和内存访问。
- 提出基于 PConv 构建的 FasterNet 家族网络,在各设备上实现更高吞吐量和更低延迟。
- 证明 FasterNet 在 ImageNet-1k 及下游任务如 COCO 目标检测/分割中的竞争力准确性。
提出的方法
- 重新评估常见 CNN 运算符在 FLOPS/FPs 性能方面的表现,聚焦内存访问瓶颈。
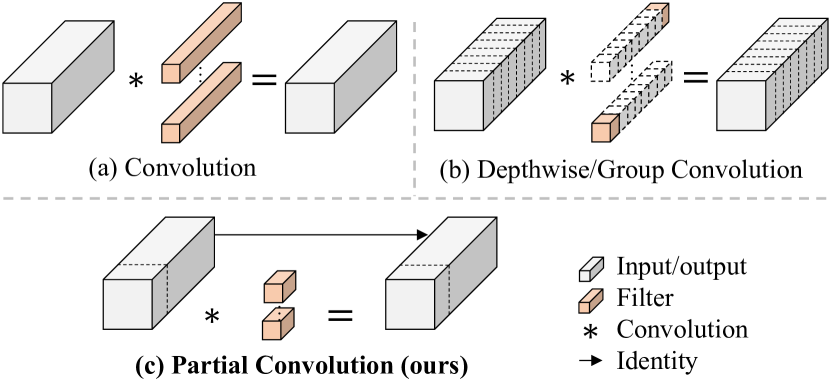
- 设计 Partial Convolution (PConv),仅对输入通道的子集应用常规卷积,其余通道保持不变。
- 将 PConv 与 PWConv 结合,形成 T 形感受野,有效捕捉空间特征。
- 将 FasterNet 块(PConv 随后是 PWConv)组装成四阶段骨干网,进行有策略的深度/宽度分配,以兼顾速度与准确性。
- 使用 BatchNorm 融合和选择性激活(GELU/ReLU),以在各设备上优化推理时延。
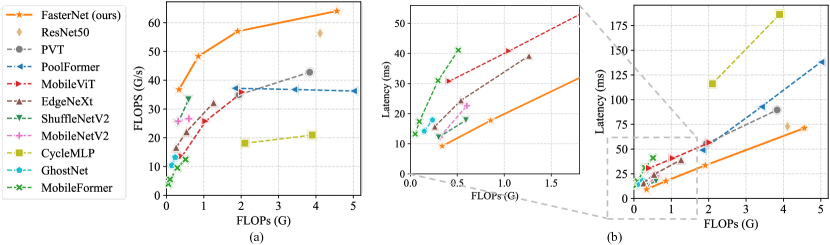
实验结果
研究问题
- RQ1更高的 FLOPS 能否被用于在常见硬件上实现更快的运行时间(latency/throughput)?
- RQ2PConv 是否能在实践中显著减少内存访问和冗余计算,从而超过深度卷积/分组卷积?
- RQ3基于 PConv 构建的 FasterNet 骨干网能否在 GPU、CPU、ARM 设备上提供最先进的速度-准确性权衡?
- RQ4FasterNet 模型在 ImageNet 分类之外的下游任务如对象检测与实例分割是否有效?
主要发现
- PConv 通过仅对部分输入通道应用卷积,在降低 FLOPs 的同时实现比 DWConv/GConv 更高的 FLOPS,同时相比常规卷积降低 FLOPs。
- 紧随 PConv 的 PWConv 能有效逼近常规卷积,同时减少内存访问且保持竞争力的精度。
- Tiny FasterNet-T0 在 GPU 上比 MobileViT-XXS 快 2.8 倍,在 CPU 上快 3.3 倍,在 ARM 上快 2.4 倍,且在 ImageNet-1k 上准确率高出 2.9%。
- Large FasterNet-L 在 ImageNet-1k 上达到 83.5% top-1 准确率,与 Swin-B/ConvNeXt-B 基线相比,GPU 吞吐量提升 36%,CPU 计算时间节省 37%。
- FasterNet 在不同设备和任务(分类、检测、分割)上提供优越的准确性-吞吐量以及准确性-时延折中,相较 CNN、ViT 以及基于 MLP 的模型。
- 在 COCO 目标检测/实例分割中,FasterNet 骨干网在相似时延下实现更高的 AP,例如 FasterNet-S 相较 ResNet50 提升了框 AP 和掩码 AP。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。