[论文解读] SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
SatCLIP 通过对 Sentinel-2 图像进行对比学习,训练一个全球性、通用定位编码器,输出经纬度嵌入,提升多样的地理空间预测并实现对未见区域的泛化。
Geographic information is essential for modeling tasks in fields ranging from ecology to epidemiology. However, extracting relevant location characteristics for a given task can be challenging, often requiring expensive data fusion or distillation from massive global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP). This global, general-purpose geographic location encoder learns an implicit representation of locations by matching CNN and ViT inferred visual patterns of openly available satellite imagery with their geographic coordinates. The resulting SatCLIP location encoder efficiently summarizes the characteristics of any given location for convenient use in downstream tasks. In our experiments, we use SatCLIP embeddings to improve prediction performance on nine diverse location-dependent tasks including temperature prediction, animal recognition, and population density estimation. Across tasks, SatCLIP consistently outperforms alternative location encoders and improves geographic generalization by encoding visual similarities of spatially distant environments. These results demonstrate the potential of vision-location models to learn meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
研究动机与目标
- 说明需要具备全球性、通用的定位编码器,其在训练区域外也能泛化。
- 提出一种 CLIP 风格的预训练目标,将坐标映射到卫星影像。
- 从 Sentinel-2 数据创建一个全球统一的预训练数据集(S2-100K)。
- 在多样的下游地理空间任务中展示嵌入的效果。
- 发布预训练的 SatCLIP 模型和数据集,供社区使用。
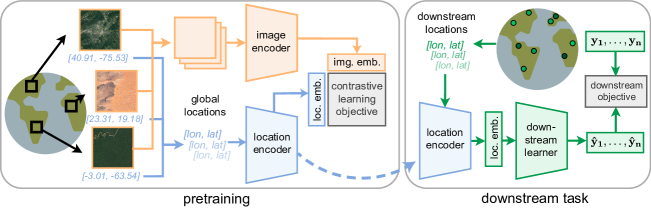
提出的方法
- 定义一个定位编码器 f_c,将(纬度,经度)映射到一个 d 维向量。
- 定义一个影像编码器 f_I,将卫星影像切片映射到一个 d 维向量。
- 使用类似 CLIP 的目标进行预训练,使定位嵌入与对应影像嵌入对齐(式(1)–(3))。
- 将 Siren(SH) 球谐函数与正弦网络用于全局坐标编码。
- 使用 ResNet 或 ViT 影像骨干网络;在训练时冻结除了最终投影层之外的参数。
- 在 A100 GPU 上,对 S2-100K 进行训练,批量大小 8k,训练 500 个 epoch。
实验结果
研究问题
- RQ1RQ1:SatCLIP 的嵌入在多样的下游地理空间任务中有多大的泛化性?
- RQ2RQ2:SatCLIP 的嵌入是否在地理上对未见大陆具有泛化能力,且无需微调样本或仅需少量样本?
- RQ3RQ3:SatCLIP 的嵌入是否能捕捉环境与社会经济地面条件的有意义的空间趋势?
主要发现
- 与基线相比,SatCLIP 在九个下游任务中的任意八个任务上实现最佳预测。
- SatCLIP 在跨大洲的地理泛化能力强,在大多数区域超越了先前的编码器。
- 对未见大陆的零-shot或少量样本微调,SatCLIP 嵌入通常更优。
- 嵌入编码出可识别的环境结构,潜在空间中存在清晰的生物群系聚类。
- 生物群系在 SatCLIP 嵌入中是可分离的,表明捕捉到了超越坐标的地面条件。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。