[论文解读] SeaFormer++: Squeeze-enhanced Axial Transformer for Mobile Visual Recognition
SeaFormer++ 引入 squeeze-enhanced Axial Transformer 模块,构建适用于移动端的语义分割与图像分类骨干, 在 ARM 设备上以低延迟实现最先进的精度。
Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement renders these methods unsuitable on the mobile device. In this paper, we introduce a new method squeeze-enhanced Axial Transformer (SeaFormer) for mobile visual recognition. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. Coupled with a light segmentation head, we achieve the best trade-off between segmentation accuracy and latency on the ARM-based mobile devices on the ADE20K, Cityscapes, Pascal Context and COCO-Stuff datasets. Critically, we beat both the mobilefriendly rivals and Transformer-based counterparts with better performance and lower latency without bells and whistles. Furthermore, we incorporate a feature upsampling-based multi-resolution distillation technique, further reducing the inference latency of the proposed framework. Beyond semantic segmentation, we further apply the proposed SeaFormer architecture to image classification and object detection problems, demonstrating the potential of serving as a versatile mobile-friendly backbone. Our code and models are made publicly available at https://github.com/fudan-zvg/SeaFormer.
研究动机与目标
- 在计算资源受限的移动设备上,阐明对高精度逐像素分割的需求。
- 提出一种轻量级 Transformer 为基础的骨干网络,在高分辨率输入下降低全局注意力计算成本。
- 设计 SEA 注意力,将全球语义提取与局部细节增强相结合。
- 构建一系列 SeaFormer 骨干以及一个轻量级分割头,以优化精度与延迟之间的权衡。
- 通过将 SeaFormer 应用于图像分类来展示其超越分割的多用途性。
提出的方法
- 引入 squeeze-enhanced Axial 注意力(SEA 注意力),通过水平和垂直挤压将复杂度降低到 O(HW)。
- 将 squeeze Axial 注意力与细节增强卷积路径结合,以恢复局部细节信息。
- 融入 squeeze axial 位置嵌入以注入位置信息。
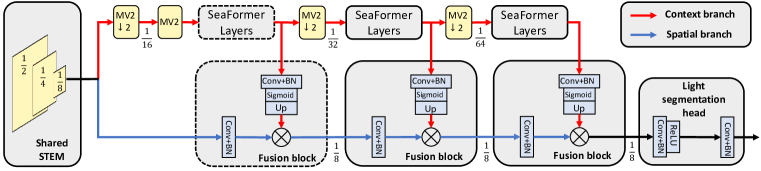
- 采用两分支架构(上下文与空间)并配备融合块,将高层语义注入到高分辨率的空间特征中。
- 附加一个轻量级分割头以实现快速移动端推理。
- 提供四种 SeaFormer 变体(Tiny, Small, Base, Large),并在 ADE20K 和 Cityscapes 上展示结果,同时进行 ImageNet-1K 分类。
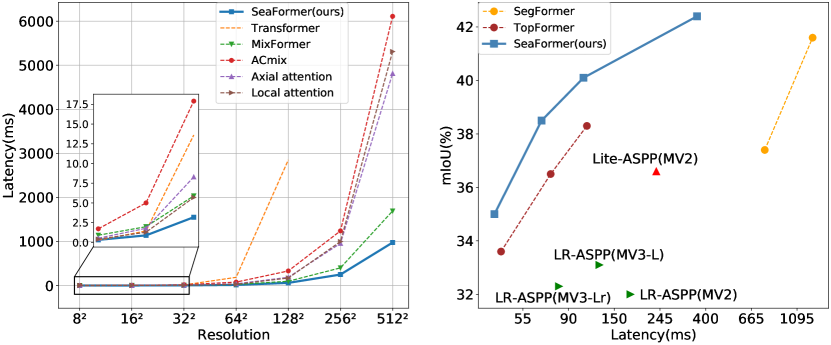
实验结果
研究问题
- RQ1如何在不牺牲精度的前提下,使自注意力在高分辨率分割任务上更适合移动端?
- RQ2一个两分支(context 与 spatial)的移动骨干是否能够在 ARM 设备上以更低的延迟实现具有竞争力的 mIoU?
- RQ3将全局 squeeze Axial 信息与局部细节增强相结合,是否优于传统注意力机制和其他高效骨干?
- RQ4SeaFormer 是否有足够的多用性,作为骨干网络在图像分类任务中也能表现出色,而不仅仅是分割?
主要发现
| 骨干网 | FLOPs | mIoU(val) | mIoU(test) | 延迟 (ms) |
|---|---|---|---|---|
| SeaFormer-T | 0.6G | 35.0 | 35.8 ± 0.35 | 40 |
| SeaFormer-S | 1.1G | 38.1 | 39.4 ± 0.25 | 67 |
| SeaFormer-B | 1.8G | 40.2 | 41.0 ± 0.45 | 106 |
| SeaFormer-L | 6.5G | 42.7 | 43.7 ± 0.36 | 367 |
- SeaFormer 变体在 ADE20K 与 Cityscapes 上相较于移动友好对手和基于 Transformer 的基线,实现了更优的精度-延迟权衡。
- SeaFormer-B 与 SeaFormer-L 在 mIoU 上更高,且延迟更低或相当于 MobileNetV3 及其他轻量骨干(如 SeaFormer-B: 40.2 mIoU,延迟 106 ms; SeaFormer-L: 42.7 mIoU,延迟 367 ms)。
- SeaFormer-S* 在 67 ms 延迟下达到 39.4 ± 0.25 mIoU,SeaFormer-L* 在 367 ms 延迟下达到 43.7 ± 0.36 mIoU,展示了在移动端延迟下的强大精度。
- 消融研究表明,细节增强与 squeeze Axial 注意力的组合相较单独使用任一组件都能带来有意义的提升。
- SeaFormer-T 在移动硬件上配备轻量级头部,且低延迟(约 40 ms 区域)提供具有竞争力的结果。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。