[论文解读] Secrets of RLHF in Large Language Models Part I: PPO
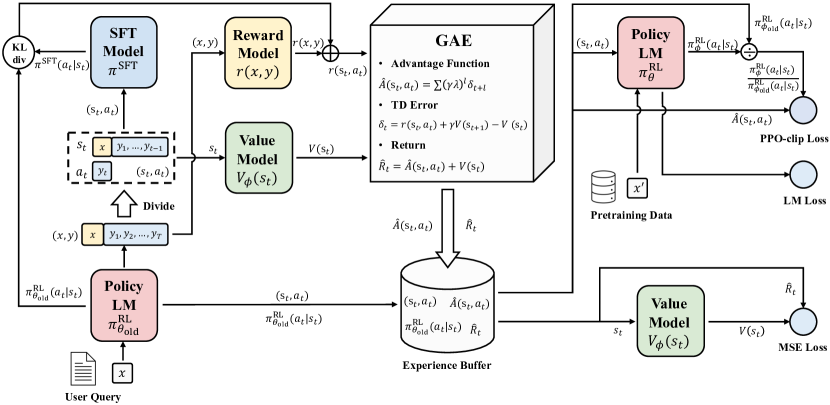
本文分析基于 PPO 的 RLHF 以对齐大型语言模型(LLMs),指出策略约束是实现稳定训练的关键,并引入 PPO-max 以提高训练稳定性和可扩展性,且发布了奖励模型和 PPO 代码。
Large language models (LLMs) have formulated a blueprint for the advancement of artificial general intelligence. Its primary objective is to function as a human-centric (helpful, honest, and harmless) assistant. Alignment with humans assumes paramount significance, and reinforcement learning with human feedback (RLHF) emerges as the pivotal technological paradigm underpinning this pursuit. Current technical routes usually include extbf{reward models} to measure human preferences, extbf{Proximal Policy Optimization} (PPO) to optimize policy model outputs, and extbf{process supervision} to improve step-by-step reasoning capabilities. However, due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle. In the first report, we dissect the framework of RLHF, re-evaluate the inner workings of PPO, and explore how the parts comprising PPO algorithms impact policy agent training. We identify policy constraints being the key factor for the effective implementation of the PPO algorithm. Therefore, we explore the PPO-max, an advanced version of PPO algorithm, to efficiently improve the training stability of the policy model. Based on our main results, we perform a comprehensive analysis of RLHF abilities compared with SFT models and ChatGPT. The absence of open-source implementations has posed significant challenges to the investigation of LLMs alignment. Therefore, we are eager to release technical reports, reward models and PPO codes, aiming to make modest contributions to the advancement of LLMs.
研究动机与目标
- Explain the RLHF framework and its training components (SFT, RM, PPO) for LLM alignment.
- Assess how reward model quality and PPO design affect policy learning and stability.
- Investigate PPO implementation details and identify factors that drive training stability and performance.
提出的方法
- Dissect RLHF framework and re-evaluate PPO inner workings to study how components affect policy training.
- Propose PPO-max, an advanced PPO variant, to enhance training stability and allow longer training steps with larger corpora.
- Develop and release Chinese and English reward models with cross-model generalization capabilities.
- Use action-space metrics (perplexity, response length, KL divergence to SFT) to monitor PPO training stability.
- Evaluate PPO-max on 7B and 13B SFT models and compare alignment with ChatGPT.
实验结果
研究问题
- RQ1How does reward model quality bound the performance of the RL policy in RLHF setups?
- RQ2What PPO design choices most influence training stability and alignment outcomes in LLMs?
- RQ3Can an optimized PPO variant (PPO-max) improve stability and enable larger training steps without harming language abilities?
- RQ4How do language and data (English vs Chinese) affect reward model training and RLHF outcomes?
主要发现
- Reward model quality directly determines the upper bound of the policy model’s performance.
- Policy constraints within PPO are critical for stable RLHF training.
- PPO-max improves training stability and supports longer training steps and larger corpora.
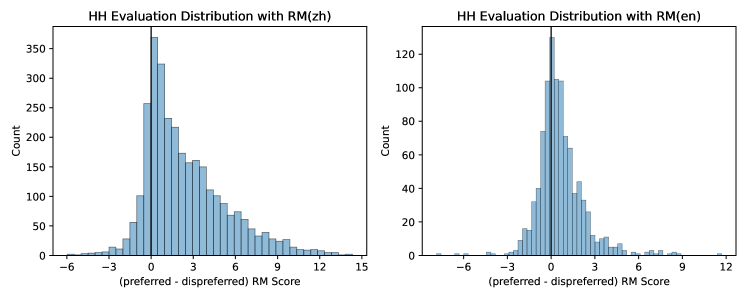
- Chinese reward models show stronger alignment with human preferences on HH evaluations than English ones in their tests.
- RLHF-trained models can sometimes better capture the deep meaning of queries and produce responses that resonate more directly with users.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。