[论文解读] Securing Large Language Models: Threats, Vulnerabilities and Responsible Practices
本文综述大型语言模型在安全与隐私方面的关注点、对对抗性攻击的脆弱性、滥用风险以及缓解策略,并提出未来研究方向。
Large language models (LLMs) have significantly transformed the landscape of Natural Language Processing (NLP). Their impact extends across a diverse spectrum of tasks, revolutionizing how we approach language understanding and generations. Nevertheless, alongside their remarkable utility, LLMs introduce critical security and risk considerations. These challenges warrant careful examination to ensure responsible deployment and safeguard against potential vulnerabilities. This research paper thoroughly investigates security and privacy concerns related to LLMs from five thematic perspectives: security and privacy concerns, vulnerabilities against adversarial attacks, potential harms caused by misuses of LLMs, mitigation strategies to address these challenges while identifying limitations of current strategies. Lastly, the paper recommends promising avenues for future research to enhance the security and risk management of LLMs.
研究动机与目标
- 在模型阶段、训练时和推理时阶段,识别由LLM使用引发的安全与隐私问题。
- 对对抗攻击和滥用带来的脆弱性及潜在危害进行分类。
- 评估并评审缓解策略,如红队/绿队测试、模型编辑、水印和检测方法。
- 提出改进LLM安全性和风险管理的未来研究方向。
提出的方法
- 将LLM脆弱性分类为模型级、训练时和推理时三个类别,并给出对策。
- 回顾现有文献关于LLM的记忆化、数据泄露和隐私风险。
- 分析代码生成的安全问题以及检测和水印方法的有效性。
- 总结缓解策略,包括红/绿队、水印和检测技术,并讨论它们的取舍。
- 识别空白并提出未来在LLM安全领域的研究方向。
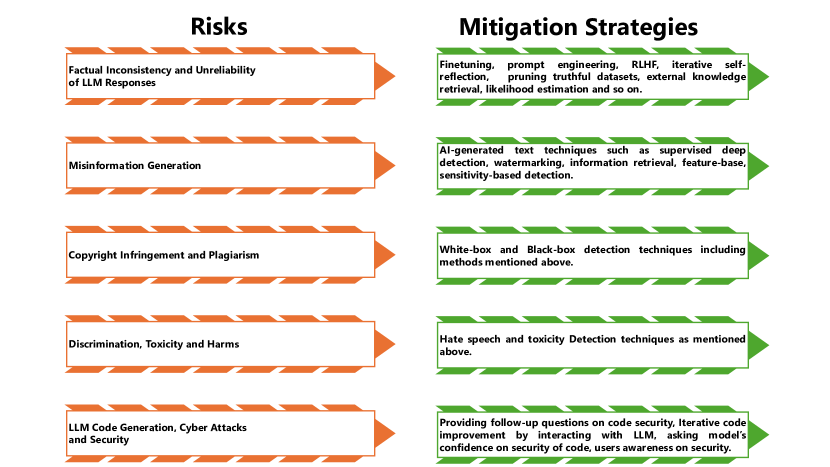
实验结果
研究问题
- RQ1与LLMs相关的主要安全与隐私问题有哪些?
- RQ2对抗性攻击如何利用LLM在模型级、训练时和推理时的脆弱性?
- RQ3LLMs可能带来哪些滥用和危害,如何进行缓解?
- RQ4当前缓解策略的局限性在哪里,未来研究应关注哪些方面?
主要发现
- 由于在大规模网络语料上的预训练,LLMs存在信息泄露和记忆化的风险。
- LLM生成的代码存在安全漏洞,可能被用于恶意用途。
- 脆弱性跨越模型级、训练时和推理时三个类别,并有各种对策。
- 缓解策略包括红队、模型编辑、水印和检测方法,每种都存在局限性和权衡。
- 本文为提升LLMs的安全性与风险管理提供了未来的研究方向。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。