[论文解读] Security and Privacy Challenges of Large Language Models: A Survey
对大型语言模型的安全与隐私挑战的全面综述,详细介绍攻击类型(提示篡改、越狱、对抗性攻击、数据污染、个人身份信息泄露)及防御机制,覆盖训练与应用领域。
Large Language Models (LLMs) have demonstrated extraordinary capabilities and contributed to multiple fields, such as generating and summarizing text, language translation, and question-answering. Nowadays, LLM is becoming a very popular tool in computerized language processing tasks, with the capability to analyze complicated linguistic patterns and provide relevant and appropriate responses depending on the context. While offering significant advantages, these models are also vulnerable to security and privacy attacks, such as jailbreaking attacks, data poisoning attacks, and Personally Identifiable Information (PII) leakage attacks. This survey provides a thorough review of the security and privacy challenges of LLMs for both training data and users, along with the application-based risks in various domains, such as transportation, education, and healthcare. We assess the extent of LLM vulnerabilities, investigate emerging security and privacy attacks for LLMs, and review the potential defense mechanisms. Additionally, the survey outlines existing research gaps in this domain and highlights future research directions.
研究动机与目标
- 提供对 LLM 在训练数据和用户方面的安全与隐私问题的透彻评估。
- 对现有针对 LLM 的攻击与防御进行分类和分析。
- 识别在运输、教育、医疗等领域的应用特定风险及其现实影响。
- 突出研究空白并提出评估协议与防御的未来方向。
提出的方法
- 对近期关于 LLM 安全与隐私的文献进行系统综述。
- 发展 LLM 安全与隐私攻击与防御的分类体系。
- 与现有综述进行比较,以突出新颖贡献与空白。
- 讨论领域特定风险及实际缓解策略。
- 概述未来研究方向与待解决的挑战。
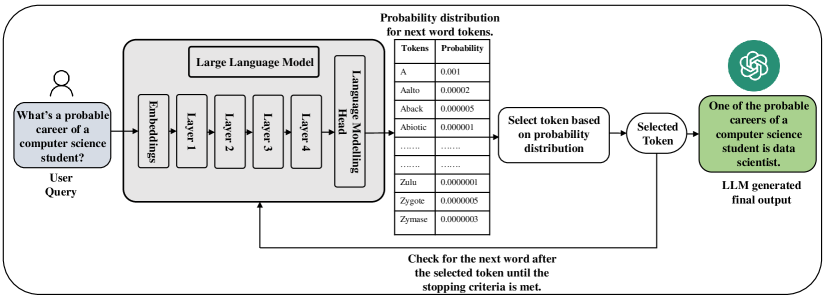
实验结果
研究问题
- RQ1针对 LLM 的主要安全攻击有哪些及其特征?
- RQ2与 LLM 相关的主要隐私风险有哪些,如何缓解?
- RQ3针对已知攻击存在哪些防御机制,它们的效力如何?
- RQ4在医疗、教育、交通等领域,LLM 可能带来哪些应用特定风险?
- RQ5评估与保障 LLM 安全方面存在哪些空白与未来方向?
主要发现
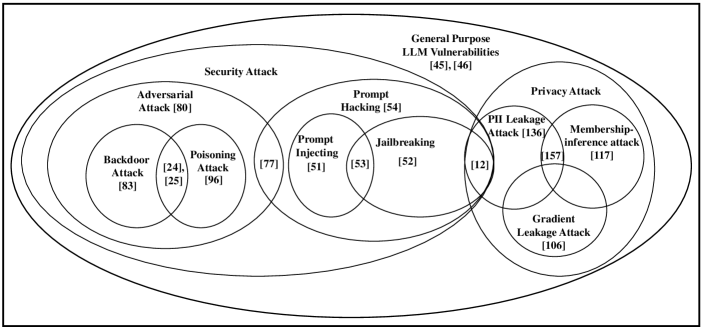
- 本文提供了关于 LLM 安全与隐私攻击的全面分类,包括提示篡改、越狱、后门、数据污染、梯度泄漏、成员资格推断以及 PII 洩漏。
- 它讨论了针对不同攻击类别的一系列防御机制和缓解策略。
- 该综述比较了近期工作,识别了当前防御与评估协议中的研究空白与局限。
- 它强调了随着 LLM 在各领域规模化和广泛应用,对安全性与隐私保护的人机交互日益增长的需求。
- 本文强调应用特定风险以及领域感知的安全/隐私体系结构的重要性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。