[论文解读] See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge-based Visual Reasoning
tldr: IPVR 是一个交互式、迭代式提示框架,用于为知识驱动的视觉推理任务提供可解释的逐步推理,通过 grounding 可视概念、让 LLM 进行推理、并验证推理以实现透明的分步解释。
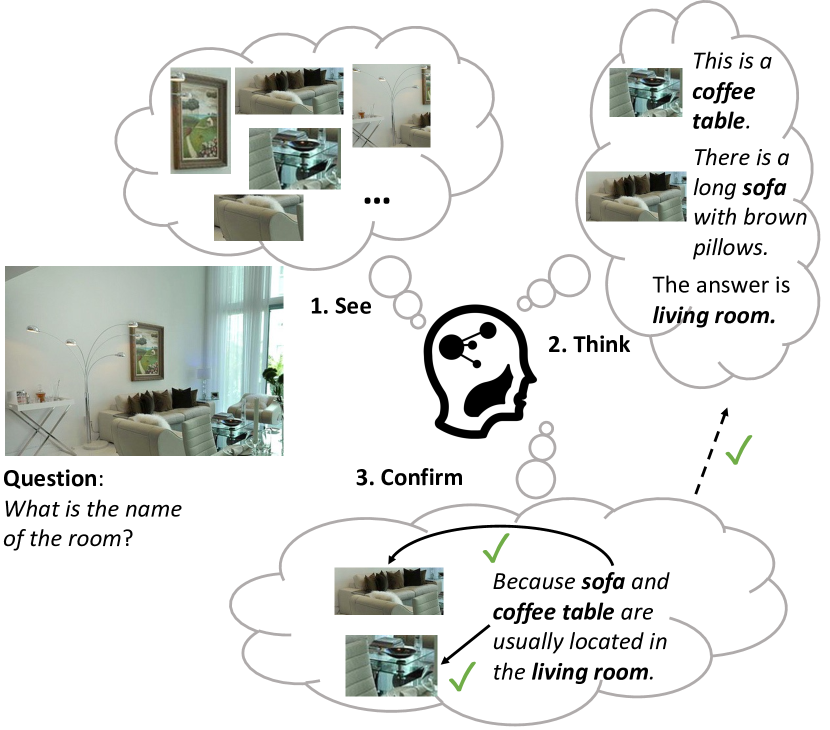
Large pre-trained vision and language models have demonstrated remarkable capacities for various tasks. However, solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect the external world knowledge, and perform step-by-step reasoning to answer the questions correctly. To this end, we propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge-based visual reasoning. IPVR contains three stages, see, think and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend to the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer. The confirm stage further uses the LLM to generate the supporting rationale to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently. We conduct experiments on a range of knowledge-based visual reasoning datasets. We found our IPVR enjoys several benefits, 1). it achieves better performance than the previous few-shot learning baselines; 2). it enjoys the total transparency and trustworthiness of the whole reasoning process by providing rationales for each reasoning step; 3). it is computation-efficient compared with other fine-tuning baselines.
研究动机与目标
- Motivate solving knowledge-based visual reasoning (KB-VQA) by combining image understanding with external knowledge and step-by-step reasoning.
- Propose a modular IPVR pipeline (see–think–confirm) that grounds concepts, generates contextual text, and iteratively refines answers.
- Enhance transparency by providing rationales and verify consistency between rationale, image content, and output.
- Improve efficiency relative to full fine-tuning while maintaining interpretability and modularity.
提出的方法
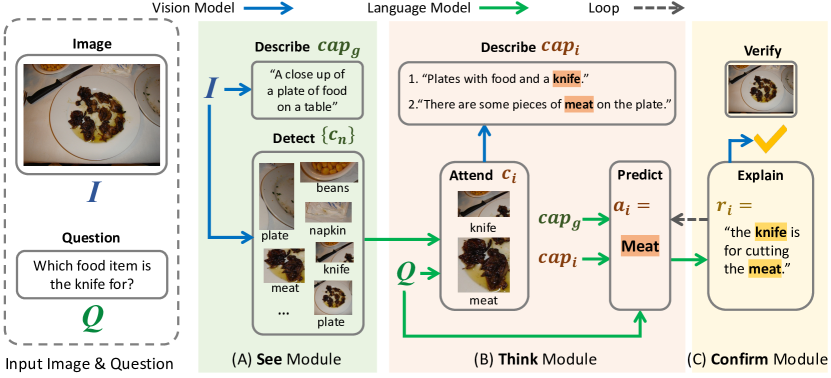
- See module detects candidate visual concepts in the image using a scene parser and produces a global image caption.
- Think module uses an in-context prompted LLM to attend to key concepts, generates regional captions for attended concepts, and predicts an answer.
- Confirm module prompts the LLM to produce a rationale and uses a cross-modality classifier to verify rationale consistency with the image before looping.
- Iterative loop repeats think and confirm until consecutive answers converge, producing an answer and a rationale trace.
- Implementation relies on Faster-RCNN for object concepts, BLIP for regional captions, OPT-66B as the LLM, and CLIP for rationale-image verification.
实验结果
研究问题
- RQ1Can interactive prompting between vision and language models achieve high accuracy on KB-VQA with few-shot prompting?
- RQ2Does iterative think–confirm prompting provide transparent, verifiable reasoning traces that improve trust and performance?
- RQ3What is the impact of each IPVR component (attend/describe, rationale generation, verification) on performance and efficiency?
- RQ4How does IPVR compare to learning-in-context baselines and finetuning-based approaches in KB-VQA benchmarks?
主要发现
- IPVR achieves better performance than prior few-shot learning baselines on KB-VQA benchmarks (OK-VQA and A-OKVQA).
- IPVR provides transparent, step-by-step reasoning traces including visual concepts, regional captions, and rationales.
- Rationale generation and its verification with a cross-modality classifier improve answer accuracy and consistency.
- IPVR remains computation-efficient compared with full fine-tuning baselines and maintains interpretability through its reasoning pipeline.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。