[论文解读] Self-Evaluation Guided Beam Search for Reasoning
作者提出一个逐步自我评估引导的随机束搜索来校准并引导多步推理在大型语言模型中,在算术、符号以及常识任务上相对于强基线在成本可比的情况下提升准确性。
Breaking down a problem into intermediate steps has demonstrated impressive performance in Large Language Model (LLM) reasoning. However, the growth of the reasoning chain introduces uncertainty and error accumulation, making it challenging to elicit accurate final results. To tackle this challenge of uncertainty in multi-step reasoning, we introduce a stepwise self-evaluation mechanism to guide and calibrate the reasoning process of LLMs. We propose a decoding algorithm integrating the self-evaluation guidance via stochastic beam search. The self-evaluation guidance serves as a better-calibrated automatic criterion, facilitating an efficient search in the reasoning space and resulting in superior prediction quality. Stochastic beam search balances exploitation and exploration of the search space with temperature-controlled randomness. Our approach surpasses the corresponding Codex-backboned baselines in few-shot accuracy by $6.34\%$, $9.56\%$, and $5.46\%$ on the GSM8K, AQuA, and StrategyQA benchmarks, respectively. Experiment results with Llama-2 on arithmetic reasoning demonstrate the efficiency of our method in outperforming the baseline methods with comparable computational budgets. Further analysis in multi-step reasoning finds our self-evaluation guidance pinpoints logic failures and leads to higher consistency and robustness. Our code is publicly available at https://guideddecoding.github.io/.
研究动机与目标
- 通过引入逐步自我评估机制,缓解多步LLM推理中的错误累积。
- 开发一个受约束的随机束搜索,在推理链的探索与利用之间取得平衡。
- 通过结合生成信心和正确性信心的自我评估分数来校准解码。
- 在算术、符号和常识推理基准上展示性能提升。
- 在不同骨干模型和提示范式下分析方法的成本与鲁棒性。
提出的方法
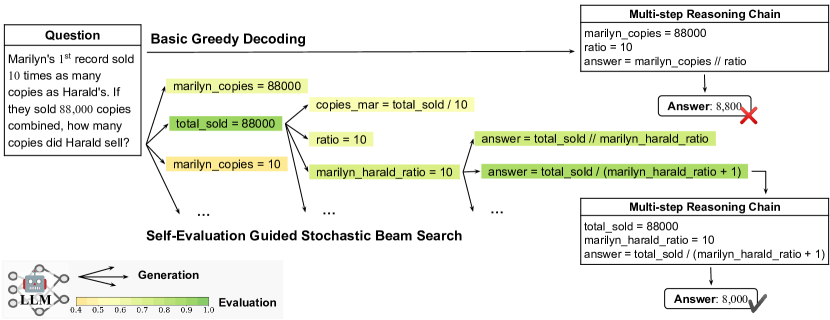
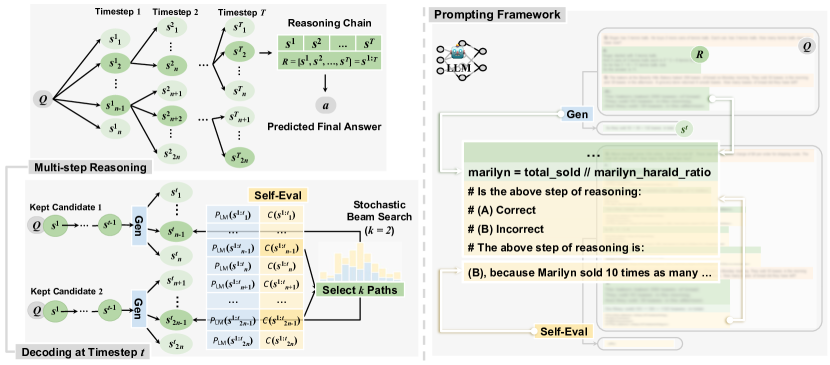
- 将推理链生成表述为一个多步解码问题,其中每一步 s^t 是一个语义上整合的令牌序列。
- 引入一个约束函数 C(s^t),为每一步编码基于LLM的正确性置信度,在目标 E(s^{1:T}) 中用于与 LM 概率进行平衡。
- 定义 E(s^{1:T}) = prod_t P_{LM_G}^λ(s^t | x, s^{1:t-1}) * C^{1-λ}(s^t) 来引导解码。
- 应用一个束大小为 k 的随机束搜索,在每束中抽样 n 个候选以形成 S,然后通过按 exp(E(s^{1:t})/τ) 的概率采样进行剪枝以鼓励多样性。
- 引入温度衰减 α,使随机性在各步骤逐步降低,稳定较长的链条。
- 使用自我评估的LLM(相同骨架,不同提示)通过 P(A | prompt_C, Q, s^{1:t}) 产生一个多项选择正确性分数 C(s^t)。
- 在算术、符号和常识基准上,对闭源和开源LLM(Codex 与 Llama-2)进行实验,比较 CoT、PAL/PoT 基线与自一致性等方法。
实验结果
研究问题
- RQ1能否通过逐步自我评估来校准并引导多步推理链的解码,以降低错误累积?
- RQ2在固定计算预算下,带可控随机性的随机束搜索是否提升推理质量?
- RQ3与强基线相比,该方法在算术、符号和常识基准上的表现如何?
- RQ4相对于自一致性和其他提示策略,成本-性能权衡如何?
- RQ5在不同任务中生成信心和正确性信心如何共同贡献自我评估分数?
主要发现
- 该方法在 GSM8K、AQuA 和 StrategyQA 基准上相对于 Codex 支撑的基线在单链和多链设置中均取得准确性提升。
- 在 Codex 的算术推理中,Ours-PAL 在 GSM8K 上达到 85.5%,在 AQuA 上达到 64.2%,分别优于基线的 80.4% 和 58.6%。
- 在 Codex 的常识推理中,Ours-CoT 在 StrategyQA 上达到 77.2%,在 CommonsenseQA 上达到 78.6%,分别超过基线的 73.2% 和 74.4%。
- 成本分析显示该方法的token使用高于自一致性但在可比预算下可超越自一致性,尤其是对于较长的推理链。
- 生成信心与正确性信心的分析表明正确性信心在捕捉逻辑错误方面更具判别力,通过 λ 平衡两者可提升结果(实验中使用 λ=0.5)。
- 该方法在较长的推理链上更具受益,随着链长增加在 StrategyQA 上获得更大提升,且在启用多样性采样和温度衰减的情况下提升仍然存在。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。