[论文解读] Self-Supervised Learning for Recommender Systems: A Survey
本综述定义了自监督推荐(SSR),提出了四类分类法(对比学习、生成式、预测式、混合式),引入 SELFRec,并分析了 SSR 方法及推荐系统的未来发展方向。
In recent years, neural architecture-based recommender systems have achieved tremendous success, but they still fall short of expectation when dealing with highly sparse data. Self-supervised learning (SSL), as an emerging technique for learning from unlabeled data, has attracted considerable attention as a potential solution to this issue. This survey paper presents a systematic and timely review of research efforts on self-supervised recommendation (SSR). Specifically, we propose an exclusive definition of SSR, on top of which we develop a comprehensive taxonomy to divide existing SSR methods into four categories: contrastive, generative, predictive, and hybrid. For each category, we elucidate its concept and formulation, the involved methods, as well as its pros and cons. Furthermore, to facilitate empirical comparison, we release an open-source library SELFRec (https://github.com/Coder-Yu/SELFRec), which incorporates a wide range of SSR models and benchmark datasets. Through rigorous experiments using this library, we derive and report some significant findings regarding the selection of self-supervised signals for enhancing recommendation. Finally, we shed light on the limitations in the current research and outline the future research directions.
研究动机与目标
- 定义 SSR 并将其与相关范式如预训练和标准对比学习区分开。
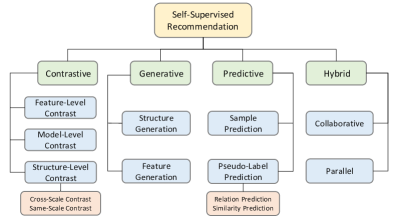
- 将 SSR 方法细分为四类:对比学习、生成式、预测式和混合式。
- 总结在 SSR 中使用的数据增强技术和训练方案。
- 提供一个开源框架(SELFRec)及经验性发现,以指导 SSR 设计。
- 讨论推荐系统中 SSR 的局限性及未来发展方向。
提出的方法
- 基于对增强数据的半自动监督和一个提升推荐的自监督任务,提出一个正式的 SSR 定义。
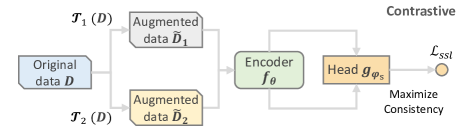
- 引入一个统一的编码器+投影头架构,能够处理图、序列和分类特征。
- 将 SSR 方法分为四类(对比学习、生成式、预测式、混合式),给出它们的目标与损失(L_rec、L_ssl)。
- 概述三种训练方案(Joint Learning、Pre-training and Fine-tuning、Integrated Learning),用于将自监督任务与推荐系统结合。
- 呈现并总结常用的序列、图和特征的数据增强技术。
- 提供一个开源库 SELFRec,包含基准测试和超过 20 种 SSR 方法。
实验结果
研究问题
- RQ1哪一个正式定义最能捕捉 SSR 及其与相关范式的区别?
- RQ2如何为推荐系统系统地对 SSR 方法进行分类?
- RQ3在 SSR 中有哪些有效的数据增强策略和训练方案?
- RQ4基于 SELFRec 的经验比较,可以得到哪些关于自监督信号提升推荐效果的洞见?
- RQ5当前 SSR 研究的局限性和有前景的方向有哪些?
主要发现
- SSR 在四个类别中受益于多样化的自监督信号,每个类别都有各自的权衡。
- 数据增强在学习可迁移表示方面发挥关键作用。
- Joint Learning 是最常见的训练方案,而对于类似 BERT 的生成式 SSR 模型,Pre-training and Fine-tuning 更为普遍。
- 一个开源的 SELFRec 库使 SSR 方法的可重复评估和基准测试成为可能。
- SELFRec 的经验结果凸显了自监督信号的有效选择以及任务与推荐目标对齐的重要性。
- 该综述指出局限性并概述在推荐领域推进 SSR 的未来方向。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。