[论文解读] Skywork: A More Open Bilingual Foundation Model
Skywork-13B 是一个双语的 13B LLM,训练于 3.2T tokens,公开发布,采用两阶段训练方案,在中文语言建模方面表现出色,并提供开放基准测试和数据。
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
研究动机与目标
- 通过发布 Skywork-13B 及中间检查点,推动大模型开发中的开源透明度。
- 提出一个两阶段预训练管线(先通用再进行领域特定增强)。
- 展示在多领域中强劲的中文语言建模与基准测试表现。
- 提供数据筛选与语料构建的细节,以实现可重复性。
- 突出数据污染问题并提出泄漏检测方法。
提出的方法
- 构建 SkyPile,这是一个大型、公开可访问的双对齐语料库,强调文本质量与分布。
- 两阶段预训练:阶段一在 SkyPile-Main 上进行通用知识预训练,阶段二在 SkyPile-STEM 与 SkyPile-Main混合上进行,以注入领域内 STEM 能力。
- 对 Transformer 解码器架构进行修改,受 LLaMA 启发(RoPE、RMSNorm、预归一化、SwiGLU、缩减 FFN 大小)。
- 使用 Megatron-LM,在 64 节点 A800 集群上结合 DP、PP 和 ZeRO-1 进行训练,采用 Flash Attention V2 提升效率。
- 通过跨领域验证损失(多个保留集)来监控训练进度,而非仅以训练损失或单一基准来评估。
- 公开 150B+ 令牌的中文语料片段(SkyPile-150B)和中间检查点,以帮助可重复性。
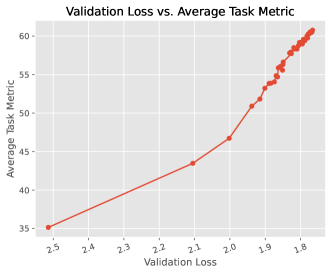
实验结果
研究问题
- RQ1两阶段、公开训练的双语大模型在通用语言建模和领域特定任务上,与同等规模的同行相比表现如何?
- RQ2领域内(STEM)持续预训练对中文及整体 STEM 任务表现有何影响?
- RQ3使用多领域验证损失进行主动监控,是否能作为预训练期间下游性能的可靠代理?
- RQ4架构选择与超参数(RoPE、RMSNorm、SwiGLU、FFN 大小)对模型性能有何影响?
- RQ5大型开放语料中存在哪些数据污染与泄漏风险,如何检测?
主要发现
| 模型 | CEVAL | CMMLU | MMLU | GSM8K |
|---|---|---|---|---|
| OpenLLaMA-13B | 27.1 | 26.7 | 42.7 | 12.4 |
| LLaMA-13B | 35.5 | 31.2 | 46.9 | 17.8 |
| LLaMA2-13B | 36.5 | 36.6 | 54.8 | 28.7 |
| Baichuan-13B | 52.4 | 55.3 | 51.6 | 26.6 |
| Baichuan2-13B | 58.1 | 62.0 | 59.2 | 52.8 |
| XVERSE-13B | 54.7 | - | 55.1 | - |
| InternLM-20B | 58.8 | - | 62.0 | 52.6 |
| Skywork-13B | 60.6 | 61.8 | 62.1 | 55.8 |
- Skywork-13B 在开放的 13B 模型中,在 CEVAL(60.6)和 MMLU(62.1)基准测试中取得领先结果。
- Skywork-13B 在 GSM8K 上达到 55.8,超越多个人数相近的开源模型。
- 在 CMMLU 上,Baichuan2-13B 领先(62.0),而 Skywork-13B 仍表现出色(61.8)。
- 在语言建模领域评估中,Skywork-13B 在包括科技(11.58)、电影(21.84)、政府(4.76)、金融(4.92)等多领域中实现最低的平均困惑度(9.42)。
- 阶段二的 STEM 重点预训练显著提升与 STEM 相关的能力与基准(如 CEVAL、GSM8K),且不影响语言建模的稳定性。
- Skywork-13B 展示出卓越的中文语言建模能力,超越许多开源模型,甚至在面向中文的基准中超过更大规模的闭源模型。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。