[论文解读] Spatial Transform Decoupling for Oriented Object Detection
STD 引入一个多分支、解耦参数预测头,用于基于 ViT 的检测器,并结合级联激活掩码,以逐步 refined 特征实现定向目标检测,在 DOTA-v1.0 与 HRSC2016 上达到最新技术水平。
Vision Transformers (ViTs) have achieved remarkable success in computer vision tasks. However, their potential in rotation-sensitive scenarios has not been fully explored, and this limitation may be inherently attributed to the lack of spatial invariance in the data-forwarding process. In this study, we present a novel approach, termed Spatial Transform Decoupling (STD), providing a simple-yet-effective solution for oriented object detection with ViTs. Built upon stacked ViT blocks, STD utilizes separate network branches to predict the position, size, and angle of bounding boxes, effectively harnessing the spatial transform potential of ViTs in a divide-and-conquer fashion. Moreover, by aggregating cascaded activation masks (CAMs) computed upon the regressed parameters, STD gradually enhances features within regions of interest (RoIs), which complements the self-attention mechanism. Without bells and whistles, STD achieves state-of-the-art performance on the benchmark datasets including DOTA-v1.0 (82.24% mAP) and HRSC2016 (98.55% mAP), which demonstrates the effectiveness of the proposed method. Source code is available at https://github.com/yuhongtian17/Spatial-Transform-Decoupling.
研究动机与目标
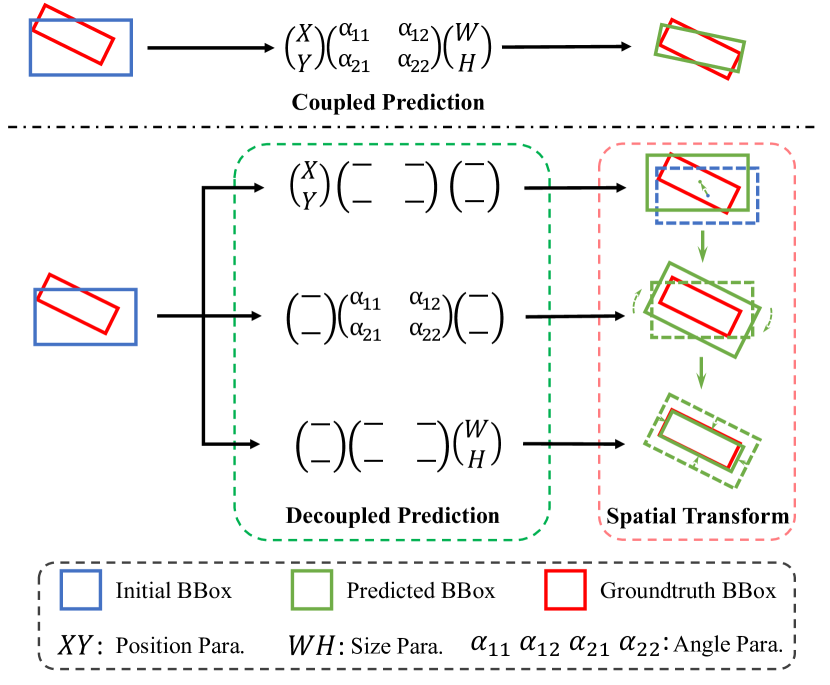
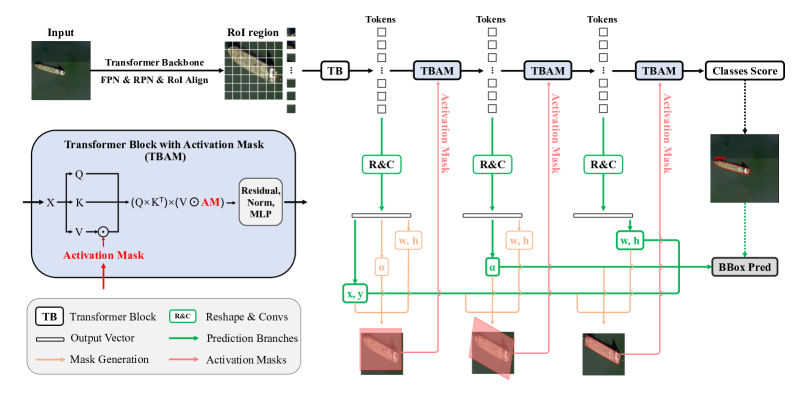
- Use a multi-branch network where each branch predicts a different spatial transform parameter (x,y), angle alpha, (w,h), and class score from progressively deeper Transformer blocks.
- Decouple feature extraction by assigning distinct feature maps from different Transformer blocks to each parameter.
- Introduce CAMs (cascaded activation masks) to provide pixel-level supervision and steer self-attention toward foreground regions.
- Train within a Faster R-CNN framework (and also show compatibility with Oriented RCNN), using ViT-based backbones pre-trained with MAE.
- Optionally pre-train MAEBBoxHead and then apply STD to achieve progressive refinement across 4 Transformer layers.
提出的方法
- Use a multi-branch network where each branch predicts a different spatial transform parameter (x,y), angle alpha, (w,h), and class score from progressively deeper Transformer blocks.
- Decouple feature extraction by assigning distinct feature maps from different Transformer blocks to each parameter. Introduce CAMs (cascaded activation masks) to provide pixel-level supervision and steer self-attention toward foreground regions.
- Compute CAMs by affine transforming a unit activation mask according to the predicted box parameters and apply them inside TBAM (Transformer Block with Activation Mask) to modulate V.
- Train within a Faster R-CNN framework (and also show compatibility with Oriented RCNN), using ViT-based backbones pre-trained with MAE.
- Optionally pre-train MAEBBoxHead and then apply STD to achieve progressive refinement across 4 Transformer layers.
实验结果
研究问题
- RQ1Can decoupled, parameter-specific feature maps improve orientation regression over coupled heads in ViT-based detectors?
- RQ2Do cascaded activation masks provide dense, stage-wise guidance that improves RoI feature refinement and overall mAP for oriented object detection?
- RQ3Is STD generalizable across different ViT backbones and RoI extraction methods while maintaining or improving accuracy?
- RQ4What is the impact of the parameter prediction order and CAM integration on STD performance?
- RQ5How does STD perform on standard oriented-object benchmarks such as DOTA-v1.0 and HRSC2016 compared to state-of-the-art methods?
主要发现
- STD 在 DOTA-v1.0 与 HRSC2016 基准测试上达到最新技术水平(例如 STD-O 在 DOTA-v1.0 的 mAP 为 82.24%,在 HRSC2016 的 mAP 为 98.55%)。
- 分层、逐层解耦的边界框参数(x,y) -> alpha -> (w,h) 提高了方向定位的准确性,相较于单特征头基线。
- CAM 提供密集的引导,使注意力图与预测参数的语义含义对齐,增强前景聚焦,减少背景混淆。
- STD 与多种骨干网络(ViT-S/ViT-B/HiViT-B)和检测器(Faster RCNN、Oriented RCNN)的兼容性强,在不同设置中均带来稳定提升。
- 消融研究证实解耦参数预测与 CAM 集成的有效性,且特定顺序(xy -> alpha -> wh)可获得最佳结果。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。